Aaron Bertrand wants you to consider using partitioned tables and the sliding window pattern to help archive old data.
That’s a great idea. In fact, I’d like to do that at my own job. I have a truly humungous log table (Terabytes) and its clustered index is already on CreatedDate so it’s a good candidate for this pattern.
The table
This is the definition of a table. Imagine it already has oodles of rows in it:
CREATE TABLE dbo.HumungousTable_NP /* Non-partitioned */ ( Id INT NOT NULL, Name NVARCHAR(100) NOT NULL, [Desc] NVARCHAR(500) NULL, LogDate DATETIME2 NOT NULL, CONSTRAINT PK_HumungousTable UNIQUE CLUSTERED (LogDate, Id), ); |
Create a partition scheme and rebuild the table
The simplest way to partition the table is to create the partition function, the partition scheme and then rebuild the table on the partition scheme like this:
/* Create the partition function */ CREATE PARTITION FUNCTION PF_MonthlySlidingWindow (DATETIME2) AS RANGE RIGHT FOR VALUES ( '20260801', /* the first partition boundary is in the near future */ '20260901', '20261001', '20261101', '20261201', '20270101' /* etc */ ); /* Create the partition scheme */ CREATE PARTITION SCHEME PS_MonthlySlidingWindow AS PARTITION PF_MonthlySlidingWindow ALL TO ([PRIMARY]); /* Rebuild the table */ CREATE UNIQUE CLUSTERED INDEX PK_HumungousTable ON dbo.HumungousTable_NP(LogDate, Id) WITH ( DROP_EXISTING = ON, ONLINE = ON ) ON PS_MonthlySlidingWindow(LogDate); |
That takes too long
There’s a problem with this. That table is truly humungous and it requires a ton of disk to complete successfully.
But I think there’s an opportunity somehow. I don’t mind if I put the entire table into the first window, I only want to adopt this sliding window strategy going forward. So maybe I can use partition switching to get where I want to be. Instead of rebuilding the table, I can:
- Create an empty partitioned table
- Add a check constraint to the original table
- Switch the data
- Drop the original table and rename the new table
The code looks the same as above, but I replace the ALTER with something like this:
/* Create the empty partitioned table */ CREATE TABLE dbo.HumungousTable_P ( Id INT NOT NULL, Name NVARCHAR(100) NOT NULL, [Desc] NVARCHAR(500) NULL, LogDate DATETIME2 NOT NULL, CONSTRAINT PK_HumungousTable_P UNIQUE CLUSTERED (LogDate, Id) ) ON PS_MonthlySlidingWindow (LogDate); /* Add the check constraint */ ALTER TABLE dbo.HumungousTable_NP ADD CONSTRAINT CK_HumungousTable_NP CHECK (LogDate < '20260101'); /* Switch */ ALTER TABLE dbo.HumungousTable_NP SWITCH TO dbo.HumungousTable_P PARTITION 1; /* Clean up */ DROP TABLE dbo.HumungousTable_NP; EXEC sp_rename 'dbo.HumungousTable_P', 'HumungousTable_NP'; |
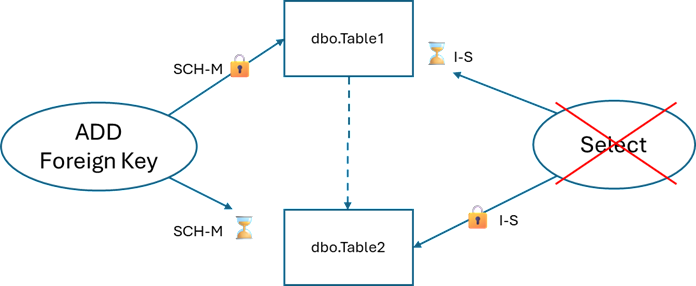
When I think about this step, it looks like this:

That still takes too long
The only problem is that adding the CHECK constraint is not online. SQL Server could make use of the available index to speed things up, but it doesn’t.
Also, if I add WITH NOCHECK when creating the constraint, it means that the constraint is enabled, but not trusted and the partition switch will fail.
Thanks Paul White for that info. Paul also points out that DBCC CHECKCONSTRAINTS is fast in this case, yet sadly does not unset the is_not_trusted when the constraint’s integrity is verified.
I asked about how to make this scenario faster a couple years ago on DBA.StackExchange: How do I add a trusted check constraint quickly.
I’m still looking for answers, or alternative solutions. If you’ve got them, leave them in the comments. If this is truly an easy fix that Microsoft hasn’t gotten around to yet, then you could add your vote on their feedback site: Use existing indexes when creating a new CHECK constraint