


How to deploy schema changes without scheduled downtime
- Introduction
- Blue-Green Deployment
- Blue-Green Deployment (Details)
- Keep Changes OLTP-Friendly
- Stage and Switch
- Careful Batching
The Blue-Green technique is a really effective way to update services without requiring downtime. One of the earliest references I could find for the Blue-Green method is in a book called Continuous Delivery by Humble and Farley. Martin Fowler also gives a good overview of it at BlueGreenDeployment. Here’s a diagram of the typical blue green method (adapted from Martin Fowler).

When using the Blue-Green method, basically nothing gets changed. Instead everything gets replaced. We start by setting up a new environment – the green environment – and then cut over to it when we’re ready. Once we cut over to the new environment successfully, we’re free to remove the original blue environment. The technique is all about replacing components rather than altering components.

Before I talk about the database (databases), notice a couple things. We need a router: Load balancers are used to distribute requests but can also be used to route requests. This enables the quick cut-over. The web servers or application servers have to be stateless as well.
What About The Database Switch?
The two databases in the diagram really threw me for a loop the first time I saw this. This whole thing only works if you can replace the database on a whim. I don’t know about you, but this simply doesn’t work for us. The Continuous Delivery book suggests putting the database into read-only mode. Implementing a temporary read-only mode for applications is difficult and rare (I’ve only ever heard of Stackoverflow doing something like this succesfully).
But we don’t do that. We want our application to be 100% online for reads and writes. We’ve modified the Blue-Green method to work for us. Here’s how we change things:
Modified Blue-Green: The Aqua Database
Leave the database where it is and decouple the database changes from the applications changes. Make database changes ahead of time such that the db can serve blue or green servers. We call this forward compatible database version “aqua”.
The changes that are applied ahead of time are “pre-migration” scripts. The changes we apply afterwards are “post-migration” scripts. More on those later. So now our modified Blue-Green migration looks like this:
Start with the original unchanged state of a system:

Add some new green servers:
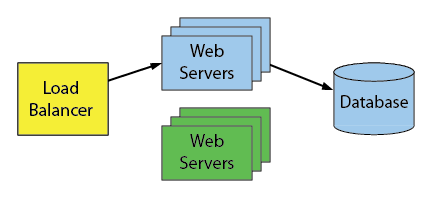
Apply the pre-migration scripts to the database. The database is now in an “aqua” state:

Do the switch!

Apply the post-migration scripts to the database. The database is now in the new “green” state:
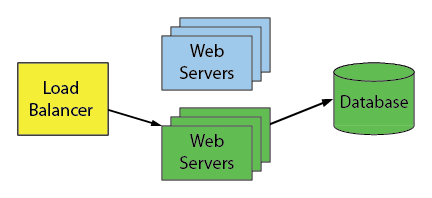
Then remove the unused blue servers when you’re ready:
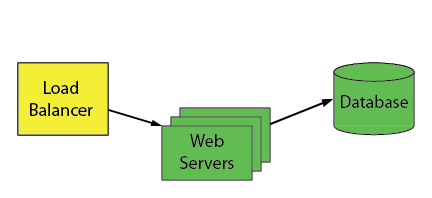
We stopped short of replacing the entire database. That “aqua” state for the database is the Blue-Green technique applied to individual database objects. In my next post, I go into a lot more detail about this aqua state with examples of what these kind of changes look like.
Ease in!
It takes a long time to move to a Blue-Green process. It took us a few years. But it’s possible to chase some short-term intermediate goals which pay off early:
Start with the goal of minimizing downtime. For example, create a pre-migration folder. This folder contains migration scripts that can be run online before the maintenance window. The purpose is to reduce the amount of offline time. New objects like views or tables can be created early, new indexes too.
Process changes are often disruptive and the move to Blue-Green is no different. It’s good then to change the process in smaller steps (each step with their own benefits).
After adding the pre-migration folder, continue adding folders. Each new folder involves a corresponding change in process. So over time, the folder structure evolves:
- The original process has all changes made during an offline maintenance window. Make sure those change scripts are checked into source control and put them in a folder called offline:
(offline) - Then add a pre-migration folder as described above:
(pre, offline) - Next add a post-migration folder which can also be run while online:
(pre, offline, post) - Drop the offline step to be fully online:
(pre, post)
Safety
Automated deployments allow for more frequent deployments. Automated tools and scripts are great at taking on the burden of menial work, but they’re not too good at thinking on their feet when it comes to troubleshooting unexpected problems. That’s where safety comes in. By safety, I just mean that as many risks are mitigated as possible. For example:
Re-runnable Scripts
If things go wrong, it should be easy to get back on track. This is less of an issue if each migration script is re-runnable. By re-runnable, I just mean that the migration script can run twice without error. Get comfortable with system tables and begin using IF EXISTS everywhere:
-- not re-runnable: CREATE INDEX IX_RUN_ONCE ON dbo.RUN_ONCE (RunOnceId); |
The re-runnable version:
-- re-runnable: IF NOT EXISTS (SELECT * FROM sys.indexes WHERE name = 'IX_RUN_MANY' AND OBJECT_NAME(object_id) = 'RUN_MANY' AND OBJECT_SCHEMA_NAME(object_id) = 'dbo') BEGIN CREATE INDEX IX_RUN_MANY ON dbo.RUN_MANY (RunManyId); END |
Avoid Schema Drift
Avoid errors caused by schema drift by asserting the schema before a deployment. Unexpected schema definitions lead to one of the largest classes of migration script errors. Errors that surprise us like “What do you mean there’s a foreign key pointing to the table I want to drop? That didn’t happen in staging!”
Schema drift is real and almost inevitable if you don’t look for it. Tools like SQL Compare are built to help you keep an eye on what you’ve got versus what’s expected. I’m sure there are other tools that do the same job. SQL Compare is just a tool I’ve used and like.
Schema Timing
When scripts are meant to be run online, duration becomes a huge factor so it needs to be measured.
When a large number of people contribute migration scripts, it’s important to keep an eye on the duration of those scripts. We’ve set up a nightly restore and migration of a sample database to measure the duration of those scripts. If any script takes a long time and deserves extra scrutiny, then it’s better to find out early.
Measuring the duration of these migration scripts helps us determine whether they are “OLTP-Friendly” which I elaborate on in Keep Changes OLTP Friendly.
Tackle Tedious Tasks with Automation
That’s a lot of extra steps and it sounds like a lot of extra work. It certainly is and the key here is automation. Remember that laziness is one of the three great virtues of a programmer. It’s the “quality that makes you go to great effort to reduce overall energy expenditure. It makes you write labor-saving programs…”. That idea is still true today.
Coming Next: Blue-Green Deployment (Details).

(cough) there’s a bug in your demo code (/cough)
The re-runnable version isn’t actually rerunnable – it’ll fail the second time. Man, I have written code like that SO MANY TIMES, hahaha. The index name in the existence check doesn’t match the name of the index you’re creating.
Otherwise, great post.
Comment by Brent Ozar — January 8, 2018 @ 4:30 pm
Okay… Nice catch and Kudos for looking so closely.
CI would have caught that 🙂
Comment by Michael J. Swart — January 8, 2018 @ 4:44 pm
I think this is pretty much the only way to deploy changes for 24/7 apps that can’t lose any data (with or without the automation).
Comment by Alex Friedman — January 9, 2018 @ 6:24 am
I have been trying to begin a similar process simply named “Database First”. I found this article a great read and a point of reference for anything tricky that might arise further down the line.
Comment by BrummieDBA — September 11, 2018 @ 3:47 am
I found this is quite often not doable; the data transform scripts must inherently transition through intermediate states for which neither old codebase nor new codebase can run at all.
I suppose I could ball up one giant transaction but at BEGIN TRANSACTION all blues can’t run and no greens can run until END TRANSACTION anyway.
Comment by Joshua Hudson — February 1, 2019 @ 12:55 pm
Hi Joshua,
Can you give me an example of where data transformation scripts must transition through an intermediate state?
One example I’m thinking of involves moving a column from xml to json.
But in that case I could maintain two columns one for xml and one for json with triggers or procedures that keep both columns in sync with eachother.
It’s difficult sometimes, but I haven’t come across really impossible situations.
I’d love to hear about the challenges that you come across.
Comment by Michael J. Swart — February 1, 2019 @ 2:36 pm
I’ve had to reassign the clustered index on a ten-million row table. This required dropping all the indices, dropping the old primary key, and creating the new clustered index, and recreating the old primary key as nonclustered, and recreating (mostly different) indices.
Oh, and the old software codebase exploded given the new clustered index because it tried to locate the primary key by finding the clustered index because it couldn’t fathom a nonclustered primary key. Well, it was right until that point about there being no clustered indexes that weren’t primary keys. This clustered index, however, had to have a NULLable column.
Comment by Joshua Hudson — February 12, 2019 @ 12:46 pm
I see. When you have to replace things like that it does get trickier.
See https://michaeljswart.com/2018/01/100-percent-online-deployments-stage-and-switch/
Or https://michaeljswart.com/2012/04/modifying-tables-online-part-5-just-one-more-thing/
It is trickier but it is possible to do these things online.
And I’m kind of taking for granted that you’ve got control over the application. If you can’t make the application forward compatible with the dB changes that you want to make then this strategy doesn’t work.
Comment by Michael J. Swart — February 12, 2019 @ 12:56 pm
[…] and I have to wonder when Kubernetes is overkill. But when you need to do dozens of deployments, or blue-green deployments, or implement stateless microservices, it’s a total […]
Pingback by Getting Kubernetes and Containers to “click” for me - SQLGene Training — April 11, 2019 @ 11:20 am
[…] This series of posts on online deployments from Michael J Swart is soooooo good (and the cartoons can’t be beat, either): https://michaeljswart.com/2018/01/100-percent-online-deployments-blue-green-deployment/ […]
Pingback by Links and Resources from "How to Architect Successful Database Changes" - by Kendra Little — November 6, 2019 @ 12:26 am
[…] blue-green deployments, […]
Pingback by How to Alter User Defined Table Types (Mostly) Online | Michael J. Swart — October 19, 2020 @ 2:41 pm
[…] Blue-Green Deployment […]
Pingback by Take Care When Scripting Batches | Michael J. Swart — September 21, 2022 @ 12:12 pm
[…] I deploy database changes, I like my scripts to be quick, non-blocking, rerunnable and resumable. I’ve discovered […]
Pingback by Deploying Resource Governor Using Online Scripts | Michael J. Swart — August 16, 2023 @ 12:07 pm