


How to deploy schema changes without scheduled downtime
Takeaway: When performing long-running modifications, I’m sure many of you enjoy using batches to increase concurrency. But I want to talk about a pitfall to be aware of. If you’re not careful, the method you use to implement batching can actually worsen concurrency.

Why Use Batches?
Even without an explicit transaction, all SQL statements are atomic – changes are all or nothing. So when you have long-running modifications to make, locks on data can be held for the duration of your query and that can be too long. Especially if your changes are intended for live databases.
But you can make your modifications in several smaller chunks or batches. The hope is that each individual batch executes quickly and holds locks on resources for a short period of time.
But care is needed. I’m going to give an example to show what I mean. The example uses the FactOnlineSales table in the ContosoRetailDW database (available as a download here). The FactOnlineSales table has
- one clustered index on
OnlineSalesKeyand no other indexes, - 12 million rows,
- and 46 thousand database pages
Metrics to Use
In this example, I want to know how long each query takes because this should let me know roughly how long locks are held.
But instead of duration, I’m going to measure logical reads. It’s a little more consistent and in the examples below it’s nicely correlated with duration.
The Straight Query
Suppose we want to remove sales data from FactOnlineSales for the “Worcester Company” whose CustomerKey = 19036. That’s a simple delete statement:
DELETE FactOnlineSales WHERE CustomerKey = 19036; |
This delete statement runs an unacceptably long time. It scans the clustered index and performs 46,650 logical reads and I’m worried about concurrency issues.
Naive Batching
So I try to delete 1,000 rows at a time. This implementation seems reasonable on the surface:
DECLARE @RC INT = 1; WHILE (@RC > 0) BEGIN DELETE TOP (1000) FactOnlineSales WHERE CustomerKey = 19036; SET @RC = @@ROWCOUNT END |
Unfortunately, this method does poorly. It scans the clustered index in order to find 1,000 rows to delete. The first few batches complete quickly, but later batches gradually get slower as it takes longer and longer to scan the index to find rows to delete. By the time the script gets to the last batch, SQL Server has to delete rows near the very end of the clustered index and to find them, SQL Server has to scan the entire table.
In fact, this last batch performs 46,521 logical reads (just 100 fewer reads than the straight delete). And the entire script performed 1,486,285 logical reads in total. If concurrency is what I’m after, this script is actually worse than the simple DELETE statement.
Careful Batching
But I know something about the indexes on this table. I can make use of this knowledge by keeping track of my progress through the clustered index so that I can continue where I left off:
DECLARE @LargestKeyProcessed INT = -1, @NextBatchMax INT, @RC INT = 1; WHILE (@RC > 0) BEGIN SELECT TOP (1000) @NextBatchMax = OnlineSalesKey FROM FactOnlineSales WHERE OnlineSalesKey > @LargestKeyProcessed AND CustomerKey = 19036 ORDER BY OnlineSalesKey ASC; DELETE FactOnlineSales WHERE CustomerKey = 19036 AND OnlineSalesKey > @LargestKeyProcessed AND OnlineSalesKey <= @NextBatchMax; SET @RC = @@ROWCOUNT; SET @LargestKeyProcessed = @NextBatchMax; END |
The delete statements in this script performed 46,796 logical reads in total but no individual delete statement performed more than 6,363.
Graphically that looks like:
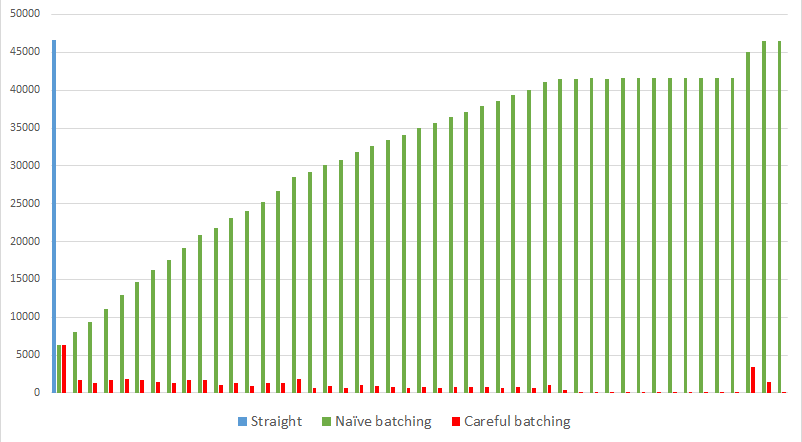
Logical Reads Per Delete
The careful batching method runs in roughly the same time as the straight delete statement but ensures that locks are not held for long.
The naive batching method runs with an order of n² complexity (compared to the expected complexity of n) and can hold locks just as long as the straight delete statement.
This underlines the importance of testing for performance.
Extra question? See if they’re answered at this follow-up post.

Ah yes, a lesson I’ve re-learned a few times. Usually it goes something like this: Start a batched operation, it’s running long so let it go over night (there’s lots of rows to go through after all), come back to work the next day to find it still running, realize I did something stupid, fix the batched query, completes in minutes.
Comment by Aaron Cooper — September 9, 2014 @ 10:28 pm
[…] Take Care When Scripting Batches – Michael J. Swart (Blog|Twitter) […]
Pingback by (SFTW) SQL Server Links 12/09/14 - John Sansom — September 12, 2014 @ 10:03 am
Short and sweet. Thank you Michael.
Comment by Srdjan — September 17, 2014 @ 2:20 pm
Hi Michael,
I really like this idea, and I’ve been applying it to a lot of my batched operations. Here’s a simplified version of an update I did. It ran through about 900k rows in 50 seconds. Let me know if you see a better way to do this.
Thanks
Comment by Erik — November 18, 2014 @ 2:15 pm
Hi Erik,
Thanks for stopping by.
In each loop, when you’re selecting the next @BatchMx value, you don’t restrict FileID to be larger than the previous @HighKey.
This means you may find yourself seeing the same poor behavior I described with the Naive batching method. But it’s actually pretty easy to measure.
Your locks will be reduced on each batch (because you’re limiting the number of rows that get updated) but I wonder about the performance of each batch:
Run the script on a test machine and collect the stats (IO/CPU) of each statement (using a trace). Compare it to the stats you get for the corresponding straight query:
Comment by Michael J. Swart — November 20, 2014 @ 9:22 am
Hi Michael,
Are you saying where I select top (N), I should be filtering on the @BatchMx variable?
I’ve reviewed lots of information about this vs. other methods using SQL Sentry monitoring tools. The only bottlenecks I’ve noticed are when I don’t/can’t have indexes that support other WHERE conditions I may use. For instance, the last time I ran this I was filtering on a bit column that I wasn’t allowed to put an index on.
I’ll try your suggestion out today and follow up.
Thanks,
Erik
Comment by Erik — November 20, 2014 @ 9:48 am
No, not on the @BatchMx variable. Where you select top (n), I would add this filter:
So presumably, SQL Server can search for keys to update where it left off.
I don’t know everything about your [FILE] table, for example, if there’s an index on Location, then the naive batching method will be very efficient.
But the main authority here is SQL Server. Test it and see. If there are no bottlenecks with the method you’re using, then it’s good.
(Also, if you don’t have an index on Location, the WHILE statement can become expensive too)
Michael
Comment by Michael J. Swart — November 20, 2014 @ 9:59 am
Okay, that makes way more sense. I’ll give that a go.
No index on Location. It’s NVARCHAR(2000) – a pretty long UNC file path – and part of a vendor product that I can’t really alter.
Thanks,
Erik
Comment by Erik — November 20, 2014 @ 10:12 am
Hi Michael,
If we could add an index on CustomerKey, which one of the three approaches would have been the best?
I guess that the first one, but it may depend on the number of records to be deleted.
Maybe if the number of records for CustomerKey = 19036 we should take into consideration the log size required to run a single delete, and then run it batched. Would, in this case with the new index, the “naive batching” be good?
I guess yes.
Thanks
Comment by Jaime — April 23, 2015 @ 2:36 am
Hi Jaime,
If we had added an index on CustomerKey, then that does change the story.
If we add an index on CustomerKey, then that index creation has the largest impact on the log. But I’m not actually worried about that.
I added the index you suggested and using the first method (the straight query), I see that the number of logical reads has jumped to 410,000! It’s not immediately obvious why. It has to do with the fact that now we have two indexes to delete from. So instead of
we have
Those lookups make all the difference
As for the second method (the naive batching method with new index). Because of that index, it automatically performs equally as well as the third method (careful batching with new index).
Comment by Michael J. Swart — April 27, 2015 @ 10:07 am
Hi Michael,
Thanks for your answer!
We were experiencing the problem with the lookups and the “surprising” increase of logical reads, and we had determined exactly the same reason.
But it is somehow disturbing that SQL performs worse with a non-clustered index in the field(s) that you use to filter the records to be deleted.
In this scenario, the lookup will always be needed, and the bigger the amount of rows to delete is, the worse the performance will be. Am I right?
Then SQL should determine that it would be a better execution plan if it chose the clustered index to delete.
Jaime
Comment by Jaime — April 27, 2015 @ 10:27 am
Hi Jaime,
SELECT statements and other queries can always perform better when appropriate indexes are added. But we pay for this performance gain by being obliged to maintain the indexes. This means that DELETE, UPDATE and INSERT statements must perform an extra operation for every extra index that’s involved. And the coordination of these actions can get expensive as you’ve discovered.
You asked another question about the performance of a delete operation and the execution plan that SQL Server chooses. I’m not quite sure I understood that. SQL Server usually chooses pretty well.
Comment by Michael J. Swart — April 27, 2015 @ 11:07 am
Michael in message 4 is updating the lookup field, that’s probably why he isn’t using an increasing index column in the where clause:
SET F.Location = REPLACE(F.Location, @Origin, @Destination)
Of course, this only works if the updated value doesn’t match any longer…
For the Original update query there is also a danger, which is not explicitly excluded:
•one clustered index on OnlineSalesKey and no other indexes,
•12 million rows,
•and 46 thousand database pages
DELETE FactOnlineSales
WHERE CustomerKey = 19036
AND OnlineSalesKey > @LargestKeyProcessed
AND OnlineSalesKey @LargestKeyProcessed
This may also skip records if duplicate values are allowed and present.
I assume the that Clustered Index is also the Primary Key in this table, so this would not be a problem.
But it may be if your search value isn’t unique for the column(s).
Comment by SQL Server Performance Tune — December 13, 2016 @ 8:40 am
Some lines have disappeared:
DELETE FactOnlineSales
WHERE CustomerKey = 19036
AND OnlineSalesKey GT @LargestKeyProcessed
AND OnlineSalesKey LTE @NextBatchMax
Imagine @LargestKeyProcessed is equal to @NextBatchMax.
No rows would be deleted and the while loop is quit, leaving records.
WHERE OnlineSalesKey GT @LargestKeyProcessed
If duplicate values are allowed, this could also skip and leave records.
Comment by SQL Server Performance Tune — December 13, 2016 @ 8:46 am
Hi there,
It turns out that this technique also works for indexes that aren’t unique.
In the original query,
@LargestKeyProcessedcan never be equal to@NextBatchMaxbecause it’s set in this query:Try it out, when the indexes are not unique, the consequence is that the batches of rows that get processed may be larger than 1000, but none will get skipped.
Comment by Michael J. Swart — December 13, 2016 @ 9:13 am
Yes, that’s right. I forgot about that. I sometimes use a similar process to update or delete rows with non-unique identifiers by setting ROWCOUNT to the number of duplicates – 1. That is not the case here, but would be the danger if you think there are only 1000 records with that specific value.
Thanks for correcting me.
Comment by SQL Server Performance Tune — December 13, 2016 @ 9:27 am
What if my original query looks like:
DELETE addr FROM customer_address addr
WHERE [BENEFICIARY_FK] IS NOT NULL
OR [CONDUCTOR_FK] IS NOT NULL
OR [THIRD_PARTY_FK] IS NOT NULL;
Comment by MlbSQL — March 6, 2018 @ 1:47 pm
Hello there, my question would be, what if my filters are different, would looks as shown below ?
–Original query
DELETE addr FROM customer_address addr
WHERE [BENEFICIARY_FK] IS NOT NULL
OR [CONDUCTOR_FK] IS NOT NULL
OR [THIRD_PARTY_FK] IS NOT NULL;
–Careful batching technique
DECLARE
@LargestKeyProcessed INT = -1,
@NextBatchMax INT,
@RC INT = 1; — rowcount
WHILE (@RC > 0)
BEGIN
SELECT TOP (1000) @NextBatchMax = customer_address_key
FROM customer_address
WHERE customer_address_key > @LargestKeyProcessed
and [BENEFICIARY_FK] IS NOT NULL
OR [CONDUCTOR_FK] IS NOT NULL
OR [THIRD_PARTY_FK] IS NOT NULL
ORDER BY customer_address_key ASC;
DELETE customer_address
WHERE [BENEFICIARY_FK] IS NOT NULL
OR [CONDUCTOR_FK] IS NOT NULL
OR [THIRD_PARTY_FK] IS NOT NULL
AND customer_address_key > @LargestKeyProcessed
AND customer_address_key <= @NextBatchMax;
SET @RC = @@ROWCOUNT;
SET @LargestKeyProcessed = @NextBatchMax;
END
Comment by MlbSQL — March 6, 2018 @ 1:50 pm
Hi MlbSQL,
That’s certainly how I would do it. The IS NOT NULL filter shows up the exact same way as the CustomerKey filter shows up in my example.
The way you’ve written it, presumably the customer_address_key is the first column of the clustered index.
Make sure to measure on a test table so that the duration of any particular query is acceptable.
I can’t by inspection tell whether any particular batching implementation is adequate.
Test and measure yourself and then look at the numbers.
Good luck
Comment by Michael J. Swart — March 6, 2018 @ 2:12 pm
Hello Michael J. Swart thanks for your answer, sounds good and I’m gonna check the timings and see how does it work, also.. do you think the same approach would work for and update statements as shown below ?
DECLARE
@LargestKeyProcessed INT = -1,
@NextBatchMax INT,
@RC INT = 1;
WHILE (@RC > 0)
BEGIN
SELECT TOP (10000) @NextBatchMax = cust_infoKey
FROM cust_info
WHERE cust_infoKey > @LargestKeyProcessed
and type=”
ORDER BY cust_infoKey ASC;
update cust_info
set type=null
where type=”
AND cust_infoKey > @LargestKeyProcessed
AND cust_infoKey <= @NextBatchMax;
SET @RC = @@ROWCOUNT;
SET @LargestKeyProcessed = @NextBatchMax;
END
Comment by MlbSQL — March 6, 2018 @ 2:49 pm
It’s difficult to continue to review examples of your code. Have a colleague of yours review it.
Good luck,
Michael
Comment by Michael J. Swart — March 6, 2018 @ 2:51 pm
Hi Michael,
I have a few very large (100 million rows+) tables which require purging of old data on a regular basis. The current table structure uses a compound key based on DATETIME and BIGINT IDENTITY. I delete in batches by the DATETIME column. I ran a small test and in fact the logical reads increased as it deleted more and more rows. How can I use your technique to improve the delete performance? Or should I rearchitect the table to just use the BIGINT IDENTITY a the key?
Thanks in advance.
Comment by Tony Green — May 10, 2018 @ 12:04 pm
Great question Tony, but I think you’ve already learned the most important lesson which is to measure this.
There’s no easy answer because every situation is different.
The thing I would focus on is the indexes that get used to find the next set of rows to process.
You say that the current structure uses a key that looks like (datetime, bigint).
Some questions I would ask are: Is it the Primary Key? Is it the clustered index? Or is it both?
Is the key exactly in that order?
Because I would expect the technique to work IF the clustered index is on (datetime) or (datetime,bigint) in that order
Comment by Michael J. Swart — May 10, 2018 @ 2:11 pm
Hi Michael,
Thank you for explaining that thoroughly. I have a table with 100 million rows and more. I am tasked to purge the data older than 9 months and for this I have created a script by using your technique (used identity column to process 10000 records). However, I am seeing excessive memory grant in my execution plan. As far as I understand, this is generally associated with varchar(x) or nvarchar(x) which are the data types of my tables. There are indexes that support my delete statement as well. Can you advise what should be looked at to get rid of that warning?
Comment by Sid — June 6, 2018 @ 11:13 am
Hi Sid,
A small batch size (like 10K records) should only need to focus on processing a small number of records, so the warning is a surprise.
But this really depends on context.
My first thought is to explore the idea that an excessive memory grant warning actually indicates a problem.
Double check (by measuring, not by inspection) that the execution plan isn’t somehow falling into the naive batching pattern.
If you reduce the size of each batch, is there a batch-size that reduces the memory grant?
Another idea is to maybe create a temporary index on the column that stores the date, and see if naive batching works (remember, naive batching only failed in my example because there was no index on CustomerKey)
Write back and let me know what solution you come up with.
Comment by Michael J. Swart — June 6, 2018 @ 11:34 am
Thanks for replying Michael. So, let me give a brief background. I have few tables where the data older than 9 months needs to be deleted. What I have done is (sorry for not clear enough earlier) the table that contains metadata contains date column and identity column and others. So, I am getting the 10000th record from this metadata table and using this as MaxRun (in the other tables) to convert into careful batching. Therefore, I am ending up deleting close to 60k – 70K records that are between first record and 10000th record. I am only using date column where I am checking if a record exist that is 9 months old, if does then continue with 10000 chunk and not in my actual delete statements. I want to make sure that my other queries are not deprived of memory when this process is running and this will be a regular maintenance job (once I have deleted almost 2 years of data). However, what I have noticed is that my actual number of rows and estimated number of rows are different. At this time, I am still investigating.
Comment by Sid — June 7, 2018 @ 8:29 am
[…] variables against values in the clustered index of the table we are updating. (Or deleting, as Michael J Swart showed in an example a few years […]
Pingback by Batching data manipulation is great as long as you do it correctly | The Desert DBA — September 15, 2018 @ 4:04 pm
Why do you / we not just select all PK-ID from the customer into a #temp-Table and run a DELETE using it:
SELECT OnlineSalesKey
INTO #tmp
FROM FactOnlineSales
WHERE CustomerKey = 19036
;
DELETE FROM t
FROM FactOnlineSales AS t
WHERE EXISTS(SELECT * FROM #temp AS tmp where tmp.OnlineSalesKey = t.OnlineSalesKey)
Comment by Thomas Franz — November 19, 2018 @ 4:26 am
Hi Thomas, you could do that. But it wouldn’t be faster and would take some extra space. The initial
SELECT INTOwill do the same scan as naive batching. Because it takes such a long time, there’s a chance that new rows with CustomerKey = 19036 can get added after the SELECT statement and then get missed with the DELETE statement.It reminds me of another technique: create a filtered index (online!) and delete it after.
Both of these methods may be simpler, but they don’t let us off the hook. We’d still have to measure the timing.
There’s probably a lot of other ways to tackle this particular problem as it’s presented. But sometimes in other situations, batching is the right choice and the point of this article is to present a way to do batching safely and online (and to measure and demonstrate that it’s safe).
Comment by Michael J. Swart — November 19, 2018 @ 9:00 am
@Thomas Franz I agree, that’s pretty much how I do it.
Get all the Clustered Index key column(s) [rather that PKey, which might not be Clustered], and also an IDENTITY, into a #TEMP table, ORDER BY the Clustered Index column(s).
That needs just one query to find all the relevant rows, and they are ordered in #TEMP by ID
Then JOIN the #TEMP table to the FactOnlineSales ON the Clustered Index column(s), and loop using a RANGE on the ID column in #TEMP. Use a WAITFOR between each delete loop iteration to allow other processes to run, and alter the batch size depending on the loop duration so that when the system gets busy the batch size reduces – if over a preset threshold reduce batch size by 50%, if under then increase batch size by 10%.
Comment by Kris — November 19, 2018 @ 5:55 pm
Would is be worth the effort to create a partition scheme, set the partition function to Customer Key and then drop the partition? Too much work? No benefit?. I’d heard that a sliding window partition was a good way to delete large blocks of data with minimal locking & blocking?
Comment by SqlNightOwl — November 19, 2018 @ 7:00 pm
When dropping partitions that way, all the indexes on the table need to be partitioned or “aligned”.
It’s not too much work, but it comes with a lot of dependencies.
Every scenario including partitioning is worth exploring. Always measure 🙂
Comment by Michael J. Swart — November 19, 2018 @ 7:11 pm
[…] I can’t begin to tell you how many terrible things you can avoid by starting your apps out using an optimistic isolation level. Read queries and write queries can magically exist together, at the expense of some tempdb.Yes, that means you can’t leave transactions open for a very long time, but hey, you shouldn’t do that anyway.Yes, that means you’ll suffer a bit more if you perform large modifications, but you should be batching them anyway. […]
Pingback by Design Tips For Scaling Systems – Curated SQL — January 4, 2019 @ 8:01 am
[…] Look at your modification queries that modify lots of rows, and try batching them […]
Pingback by Index Key Column Order And Locking – Erik Darling Data — May 30, 2019 @ 9:55 am
[…] Here is a good example you should read to illustrate testing the performance of batches. […]
Pingback by Using T-SQL to Insert, Update, Delete Millions of Rows – MlakarTechTalk — October 3, 2019 @ 9:38 pm
Michael,
Thank you and others for comments on the options to minimize lock duration. There are many and all need to be tested.
Comment by Wilson Hauck — November 21, 2019 @ 10:29 am
[…] Use larger batch sizes […]
Pingback by Improving The Performance of RBAR Modifications | Erik Darling Data — February 15, 2021 @ 2:25 pm
[…] That way you can find the sweet spot for your own deletes based on your server’s horsepower, concurrency demands from other queries (some of which might be trying to take table locks themselves), the amount of data you need to delete, etc. Use the techniques Michael J. Swart describes in Take Care When Scripting Batches. […]
Pingback by Concurrency Week: How to Delete Just Some Rows from a Really Big Table - Brent Ozar Unlimited® — March 10, 2021 @ 1:00 am
Shared this with my team today! Still so useful after so many years. Thanks for all the help!
Comment by Scott MacLellan — June 24, 2021 @ 3:08 pm
Thanks Scott! Good to hear from you.
Yes, that post is like evergreen
Comment by Michael J. Swart — June 24, 2021 @ 3:18 pm
[…] when modifications need to hit a significant number of rows, I want to think about batching things. That might not always be possible, but it’s certainly a kinder way to do […]
Pingback by Why Large Modifications Are Never Fast – Erik Darling Data — June 27, 2021 @ 10:19 pm
[…] Are you modification queries biting off more than they should chew? […]
Pingback by Steps For Getting Rid Of NOLOCK Hints – Erik Darling Data — September 24, 2021 @ 1:16 pm
[…] If you would like to use it on production environment, please play with delay time and number of records that you are removing in one batch. If you have more sophisticated demand on deletion, and you have even bigger constraint on performance, please give this a read: https://michaeljswart.com/2014/09/take-care-when-scripting-batches/ […]
Pingback by How to delete small portion of data from BIG table? - Next Level BI Blog — November 15, 2021 @ 10:56 am
[…] make users feel some pain? Have your app be unusable for big chunks of time because you refuse to chunk your modifications. Worse, if enough queries get backed up behind one of these monsters, you can end up running out of […]
Pingback by Software Vendor Mistakes With SQL Server: Modifying Millions of Rows At A Time – Erik Darling Data — December 22, 2021 @ 10:10 am
[…] Just read this post from Michael J. Swart about batching modifications. […]
Pingback by Adventures In Foreign Keys 1: Setting Up Foreign Keys in Stack Overflow - Brent Ozar Unlimited® — December 29, 2021 @ 6:55 am
[…] Batching modifications is one way to avoid lock escalation when you need to modify a lot of rows, though it isn’t always possible to do this. If for some reason you need to roll the entire change back, you’d have to keep track of all the committed batches somewhere, or wrap the entire thing in a transaction (which would defeat the purpose, largely). […]
Pingback by In SQL Server, Isolation Levels Don’t Control Locking – Erik Darling Data — May 23, 2022 @ 11:32 am
Any ideas on how this would work if the primary key was a guid?
Comment by Gene B. Torres — May 23, 2022 @ 3:24 pm
The clustered index is the important thing.
Exec sp_help ‘tablename’
To see what the clustered index is. It’s often the primary key.
It doesn’t matter what type it is.
The main lesson from this post is that whatever you code, you measure to see if the cost increases with each batch.
Comment by Michael J. Swart — May 23, 2022 @ 3:53 pm
[…] I wrote Take Care When Scripting Batches, I wanted to guard against a common pitfall when implementing a batching solution (n-squared […]
Pingback by Batching Follow-Up | Michael J. Swart — September 21, 2022 @ 12:00 pm
[…] don’t mean to put anyone off from using batching to make large modifications more […]
Pingback by Batching Modification Queries Is Great Until… – Erik Darling Data — October 10, 2022 @ 9:07 am
[…] If you’re looking for a more efficient way to delete data, I’d start here. […]
Pingback by Truncate with where clause — March 14, 2023 @ 3:42 pm
[…] delete runs daily as part of SQL job. I am doing Naive Batching as described in Take Care When Scripting Batches (by Michael J. Swart) to delete rows until all of the rows are […]
Pingback by Optimize delete query in SQL Server 2008 R2 SP1 — March 25, 2023 @ 2:03 am
How do you handle batching with no primary key and a clustered index which are both char (one is char(30) and the other is char(16))? I inherited a table like this and records need to be deleted out of it while users and reports are accessing this data. How would you’re approach be or can you direct me to a website that talks about my kind of use case?
Comment by Eric — December 1, 2023 @ 11:02 am
Visit https://michaeljswart.com/2022/09/batching-follow-up/
And look for “What if the clustered index is not unique”
Comment by Michael J. Swart — December 1, 2023 @ 11:11 am