That’s a great idea. In fact, I’d like to do that at my own job. I have a truly humungous log table (Terabytes) and its clustered index is already on CreatedDate so it’s a good candidate for this pattern.
The table
This is the definition of a table. Imagine it already has oodles of rows in it:
CREATETABLE dbo.HumungousTable_NP/* Non-partitioned */(
Id INTNOTNULL,
Name NVARCHAR(100)NOTNULL,[Desc]NVARCHAR(500)NULL,
LogDate DATETIME2NOTNULL,CONSTRAINT PK_HumungousTable
UNIQUECLUSTERED(LogDate, Id),);
CREATE TABLE dbo.HumungousTable_NP /* Non-partitioned */
(
Id INT NOT NULL,
Name NVARCHAR(100) NOT NULL,
[Desc] NVARCHAR(500) NULL,
LogDate DATETIME2 NOT NULL,
CONSTRAINT PK_HumungousTable
UNIQUE CLUSTERED (LogDate, Id),
);
Create a partition scheme and rebuild the table
The simplest way to partition the table is to create the partition function, the partition scheme and then rebuild the table on the partition scheme like this:
/* Create the partition function */CREATEPARTITIONFUNCTION PF_MonthlySlidingWindow (DATETIME2)ASRANGERIGHTFORVALUES('20260801',/* the first partition boundary is in the near future */'20260901','20261001','20261101','20261201','20270101'/* etc */);/* Create the partition scheme */CREATEPARTITIONSCHEME PS_MonthlySlidingWindow
ASPARTITION PF_MonthlySlidingWindow
ALLTO([PRIMARY]);/* Rebuild the table */CREATEUNIQUECLUSTEREDINDEX PK_HumungousTable
ON dbo.HumungousTable_NP(LogDate, Id)WITH(DROP_EXISTING=ON,ONLINE=ON)ON PS_MonthlySlidingWindow(LogDate);
/* Create the partition function */
CREATE PARTITION FUNCTION PF_MonthlySlidingWindow (DATETIME2)
AS RANGE RIGHT
FOR VALUES
(
'20260801', /* the first partition boundary is in the near future */
'20260901',
'20261001',
'20261101',
'20261201',
'20270101' /* etc */
);
/* Create the partition scheme */
CREATE PARTITION SCHEME PS_MonthlySlidingWindow
AS PARTITION PF_MonthlySlidingWindow
ALL TO ([PRIMARY]);
/* Rebuild the table */
CREATE UNIQUE CLUSTERED INDEX PK_HumungousTable
ON dbo.HumungousTable_NP(LogDate, Id)
WITH ( DROP_EXISTING = ON, ONLINE = ON )
ON PS_MonthlySlidingWindow(LogDate);
That takes too long
There’s a problem with this. That table is truly humungous and it requires a ton of disk to complete successfully.
But I think there’s an opportunity somehow. I don’t mind if I put the entire table into the first window, I only want to adopt this sliding window strategy going forward. So maybe I can use partition switching to get where I want to be. Instead of rebuilding the table, I can:
Create an empty partitioned table
Add a check constraint to the original table
Switch the data
Drop the original table and rename the new table
The code looks the same as above, but I replace the ALTER with something like this:
/* Create the empty partitioned table */CREATETABLE dbo.HumungousTable_P(
Id INTNOTNULL,
Name NVARCHAR(100)NOTNULL,[Desc]NVARCHAR(500)NULL,
LogDate DATETIME2NOTNULL,CONSTRAINT PK_HumungousTable_P
UNIQUECLUSTERED(LogDate, Id))ON PS_MonthlySlidingWindow (LogDate);/* Add the check constraint */ALTERTABLE dbo.HumungousTable_NPADDCONSTRAINT CK_HumungousTable_NP
CHECK(LogDate <'20260101');/* Switch */ALTERTABLE dbo.HumungousTable_NPSWITCHTO dbo.HumungousTable_PPARTITION1;/* Clean up */DROPTABLE dbo.HumungousTable_NP;EXECsp_rename'dbo.HumungousTable_P','HumungousTable_NP';
/* Create the empty partitioned table */
CREATE TABLE dbo.HumungousTable_P
(
Id INT NOT NULL,
Name NVARCHAR(100) NOT NULL,
[Desc] NVARCHAR(500) NULL,
LogDate DATETIME2 NOT NULL,
CONSTRAINT PK_HumungousTable_P
UNIQUE CLUSTERED (LogDate, Id)
)
ON PS_MonthlySlidingWindow (LogDate);
/* Add the check constraint */
ALTER TABLE dbo.HumungousTable_NP
ADD CONSTRAINT CK_HumungousTable_NP
CHECK (LogDate < '20260101');
/* Switch */
ALTER TABLE dbo.HumungousTable_NP
SWITCH TO dbo.HumungousTable_P PARTITION 1;
/* Clean up */
DROP TABLE dbo.HumungousTable_NP;
EXEC sp_rename 'dbo.HumungousTable_P', 'HumungousTable_NP';
When I think about this step, it looks like this:
That still takes too long
The only problem is that adding the CHECK constraint is not online. SQL Server could make use of the available index to speed things up, but it doesn’t.
Also, if I add WITH NOCHECK when creating the constraint, it means that the constraint is enabled, but not trusted and the partition switch will fail.
Thanks Paul White for that info. Paul also points out that DBCC CHECKCONSTRAINTS is fast in this case, yet sadly does not unset the is_not_trusted when the constraint’s integrity is verified.
I’m still looking for answers, or alternative solutions. If you’ve got them, leave them in the comments. If this is truly an easy fix that Microsoft hasn’t gotten around to yet, then you could add your vote on their feedback site: Use existing indexes when creating a new CHECK constraint
It’s hard to destroy data. Even when a column is dropped, the data is still physically there on the data page. We can use the undocumented/unsupported command DBCC PAGE to look at it.
Example
First, create a table based on English values from sys.messages:
use tempdb;go/* create table based on english values from sys.messages */DROPTABLEIFEXISTS #MyMessages;CREATETABLE #MyMessages (
message_id INTNOTNULLPRIMARYKEY,
severity INTNOTNULL,textNVARCHAR(MAX));GOINSERT #MyMessages (message_id, severity,text)SELECT message_id, severity,textFROMsys.messagesWHERE language_id =1033;GO
use tempdb;
go
/* create table based on english values from sys.messages */
DROP TABLE IF EXISTS #MyMessages;
CREATE TABLE #MyMessages (
message_id INT NOT NULL PRIMARY KEY,
severity INT NOT NULL,
text NVARCHAR(MAX)
);
GO
INSERT #MyMessages (message_id, severity, text)
SELECT message_id, severity, text
FROM sys.messages
WHERE language_id = 1033;
GO
Then drop the column severity
/* drop column severity */ALTERTABLE #MyMessages
DROPCOLUMN severity;GO
/* drop column severity */
ALTER TABLE #MyMessages
DROP COLUMN severity;
GO
The Task
Without restoring a backup, let’s try to answer the following question: “What was the severity of the message with message_id = 9015?”
We do that by
Finding the physical page
Looking at the memory dump with DBCC Page
Finding the data and making sense of it
Finding the physical page
Start by finding the physical location of the row. It’s address is three numbers, FileId, PageId, SlotId.
SELECTsys.fn_PhysLocFormatter(%%physloc%%)FROM #MyMessages
WHERE message_id =9015
SELECT sys.fn_PhysLocFormatter(%%physloc%%)
FROM #MyMessages
WHERE message_id = 9015
So as an example, the output will be like: (8:286:30). The first number is the FileId, the second is the PageId and the third is the SlotId. Remember those numbers.
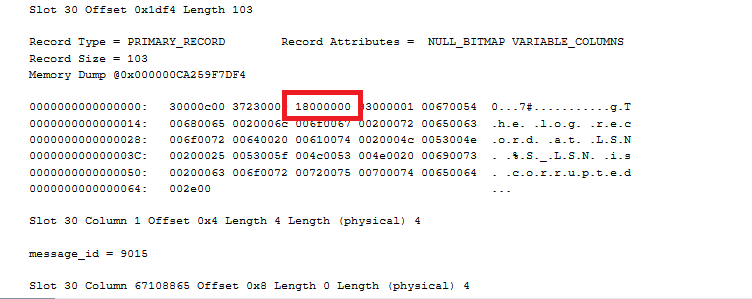
Use DBCC PAGE to look at the page
Turn on trace flag 3604 to see results. DBCC PAGE takes parameters DatabaseName, FileId and PageId as an input. The fourth parameter is like an output type. Use 3.
To retrieve our value, we look for the dropped column, it’s helpfully listed as DROPPED = NULL.
That NULL isn’t to helpful, but the extra info right before DROPPED = NULL Looks like: Slot 30 Column 67108865 Offset 0x8 Length 0 Length (physical) 4
We can use that information. In this example, the offset is 0x8 and the physical length is 4.
This means, at offset hex 0x8 which is 8, read 4 bytes. But where do we read that? At the memory dump for the row:
Each hex number is half a byte, so starting 16 hex digits over, look at the next 4 bytes (8 hex digits). That gives us 18000000. That’s a hex number whose bytes have been reversed.
So starting with: 18000000,
Split that into bytes: 18 00 00 00
Reverse it like Missy Elliot: 00 00 00 18.
Use a programming calculator to go from hex: 0x00000018
To decimal: 24
The severity of the message with message_id = 9015 was indeed 24.
If you define a clustered index that’s not unique, SQL Server will add a hidden 4-byte column called UNIQUIFIER. You can’t see it directly but it’s there. When you add a row whose key is a duplicate of an existing row, the new row gets a new unique value for it’s uniqueifier. If you add over 2.1 billion rows with the same key, the uniquifier value exceeds the limit and you will see error 666.
A while ago, we nearly got into trouble because of a bad choice for clustering key that went undetected for so long.
Is your database nearing trouble?
Here’s a script that might help you find out.
selecttop100OBJECT_SCHEMA_NAME(t.object_id)as[schema],
t.nameas[table],
i.nameas[index],
i.type_desc,
i.is_unique,
s.range_high_key,
s.equal_rowsfromsys.indexes i
innerjoinsys.tables t
on i.object_id= t.object_idcrossapplysys.dm_db_stats_histogram(i.object_id, i.index_id) s
leftjoinsys.index_columns ic
on ic.object_id= i.object_idand ic.index_id= i.index_idand ic.index_column_id=2where
i.index_id=1and i.is_unique=0and ic.index_idisnullorderby s.equal_rowsdesc
select top 100
OBJECT_SCHEMA_NAME(t.object_id) as [schema],
t.name as [table],
i.name as [index],
i.type_desc,
i.is_unique,
s.range_high_key,
s.equal_rows
from
sys.indexes i
inner join
sys.tables t
on i.object_id = t.object_id
cross apply
sys.dm_db_stats_histogram(i.object_id, i.index_id) s
left join
sys.index_columns ic
on ic.object_id = i.object_id
and ic.index_id = i.index_id
and ic.index_column_id = 2
where
i.index_id = 1
and i.is_unique = 0
and ic.index_id is null
order by s.equal_rows desc
This query looks at clustered indexes that are not unique. It looks through the stats histogram and reports any with a high “EQUAL” range count.
If any of the equal_rows values are nearing 2 billion, then look out.
Kimberly Tripp always advocated uniqueness as a property of a good clustering index. That implies that equal_rows in the results here should be closer to 1 – nowhere near 2 billion!. So Microsoft’s advice holds true: “review tables that rely on uniqueifiers and proactively work to improve its design”.
If you find instances where any of the equal_rows are above 10000, you might choose to look closer.
Update: A careful look at the script will tell you that I’m excluding clustered indexes with more than one key column from the results. It’s still possible to get into trouble with multi-column clustered indexes, but because the stats histogram only focuses on the first column, this script can’t (easily) warn you about those times. See the comment section for lots more discussion.
MIN_ACTIVE_ROWVERSION() is a system function that returns the lowest active rowversion value in the current database. Its use then is very similar to @@DBTS.
In fact, the docs for MIN_ACTIVE_ROWVERSION() (currently) say:
If there are no active values in the database, MIN_ACTIVE_ROWVERSION() returns the same value as @@DBTS + 1.
Does it though? You may be tempted then to replace some of your @@DBTS expressions with expressions like this:
Broken example
/* This is not always equivalent to @@DBTS */SELECTCAST(MIN_ACTIVE_ROWVERSION()-1AS rowversion);
/* This is not always equivalent to @@DBTS */
SELECT CAST(MIN_ACTIVE_ROWVERSION() - 1 AS rowversion);
Try to figure out why this is broken before reading further.
The problem
The problem occurs when the values get large. In fact you can reproduce this behavior with:
/* This may also give unexpected results */SELECTCAST(0x017fffffff -1AS rowversion);
/* 0x000000007FFFFFFE? Where did that leading one go? */
/* This may also give unexpected results */
SELECT CAST(0x017fffffff - 1 AS rowversion);
/* 0x000000007FFFFFFE? Where did that leading one go? */
But why?
The issue is in the expression MIN_ACTIVE_ROWVERSION() - 1. SQL Server will try to subtract an int from a binary(8). To do that, it converts only the last four bytes of the binary(8) value to an int. It does that happily without any errors or warnings, even if the first four bytes are not zeros.
A fix
When we subtract, we want bigint arithmetic:
/* This gives the value we want*/SELECTCAST(CAST(MIN_ACTIVE_ROWVERSION()ASBIGINT)-1AS rowversion);
/* This gives the value we want*/
SELECT CAST(CAST(MIN_ACTIVE_ROWVERSION() AS BIGINT) - 1 AS rowversion);
Takeaway: If you want to extract rows from a table periodically as part of an ETL operation and if you use Read Committed Snapshot Isolation (RCSI), be very careful or you may miss some rows.
Yesterday, Kendra Little talked a bit about Lost Updates under RCSI. It’s a minor issue that can pop up after turning on RCSI as the default behavior for the Read Committed isolation level. But she doesn’t want to dissuade you from considering the option and I agree with that advice.
In fact, even though we turned RCSI on years ago, by a bizarre coincidence, we only came across our first RCSI-related issue very recently. But it wasn’t update related. Instead, it has to do with an ETL process. To explain it better, consider this demo:
Set up a database called TestRCSI
CREATEDATABASE TestRCSI;
ALTERDATABASE TestRCSI SET READ_COMMITTED_SNAPSHOT ON;
CREATE DATABASE TestRCSI;
ALTER DATABASE TestRCSI SET READ_COMMITTED_SNAPSHOT ON;
use TestRCSI;
CREATE TABLE LOGS (
LogId INT IDENTITY PRIMARY KEY,
Value CHAR(100) NOT NULL DEFAULT '12345'
);
INSERT LOGS DEFAULT VALUES;
INSERT LOGS DEFAULT VALUES;
INSERT LOGS DEFAULT VALUES;
Create a procedure to extract new rows
We want to extract rows from a table whose LogId is greater than any LogId we’ve already seen. That can be done with this procedure:
CREATEPROCEDURE s_FetchLogs ( @AfterLogId INT)ASSELECT LogId, ValueFROM LOGS
WHERE LogId > @AfterLogid;
GO
CREATE PROCEDURE s_FetchLogs ( @AfterLogId INT )
AS
SELECT LogId, Value
FROM LOGS
WHERE LogId > @AfterLogid;
GO
That seems straightforward. Now every time you perform that ETL operation, just remember the largest LogId from the results. That value can be used the next time you call the procedure. Such a value is called a “watermark”.
Multiple sessions doing INSERTs concurrently
Things can get a little tricky if we insert rows like this: Session A:
INSERT LOGS DEFAULTVALUES; /* e.g. LogId=4 */
INSERT LOGS DEFAULT VALUES; /* e.g. LogId=4 */
Session B:
BEGINTRANINSERT LOGS DEFAULTVALUES; /* e.g. LogId=5 *//* No commit or rollback, leave this transaction open */
BEGIN TRAN
INSERT LOGS DEFAULT VALUES; /* e.g. LogId=5 */
/* No commit or rollback, leave this transaction open */
Session A:
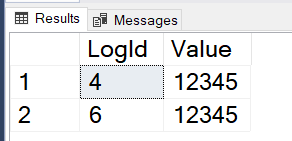
INSERT LOGS DEFAULTVALUES; /* e.g. LogId=6 */EXEC s_FetchLogs @AfterLogId =3;
And you may start to see what the issue is. Row 5 hasn’t been committed yet and if you’re wondering whether it will get picked up the next time the ETL is run, the answer is no. The max row in the previous results is 6, so the next call will look like this:
EXEC s_FetchLogs @AfterLogId =6;
EXEC s_FetchLogs @AfterLogId = 6;
It will leave the row with LogId = 5 behind entirely. This ETL process has missed a row.
What’s the deal?
It’s important to realize that there’s really no defect here. There is no isolation level that really guarantees “sequentiality” or “contiguousness” of inserted sequences this way. That property is not really guaranteed by any isolation level or by any of the letters in ACID. But it still is behavior that we want to understand and do something about.
Transactions do not really occur at a single point in time, they have beginnings and ends and we can’t assume the duration of a transaction is zero. Single-statement transactions are no exception. The important point is that the time a row is created is not the same time as it’s committed. And when several rows are created by many sessions concurrently, the order that rows are created are not necessarily the order that they’re committed!
With any version of READ COMMITTED, the rows created by other sessions only become visible after they’re committed and if the rows are not committed sequentially, they don’t become visible sequentially. This behavior is not particular to identity column values, it also applies to:
Really any kind of DateTime column with “Now” as the default
So if:
columns like these are used as watermarks for an ETL strategy
and the table experiences concurrent inserts
and Read Committed Snapshot Isolation is enabled
then the process is vulnerable to this missed row issue.
This issue feels like some sort of Phantom Read problem, but it’s not that exactly. Something different is going on in an interesting way. Rows are inserted in a table such that column values are expected to always increase. That expectation is the interesting thing. So when transactions are committed “out of order” then those rows become visible out of order. The expectation is not met and that’s the issue.
Solutions (pessimistic locking)
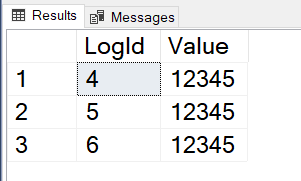
If you turn off RCSI and run the demo over again, you’ll notice that running s_FetchLogs in Session A will be blocked until the transaction in Session B is committed. When Session A is finally unblocked, we get the full results (including row 5) as expected:
Here’s why this works. Any newly created (but uncommitted) row will exist in the table. But the transaction that created it still has an exclusive lock on it. Without RCSI, if another session tries to scan that part of the index it will wait to grab a shared lock on that row. Problem solved.
But turning off RCSI is overkill. We can be a little more careful. For example, instead of leaving RCSI off all together, do it just for the one procedure like this:
CREATE OR ALTER PROCEDURE s_FetchLogs ( @AfterLogId INT )
AS
SELECT LogId, Value
FROM LOGS WITH(READCOMMITTEDLOCK)
WHERE LogId > @AfterLogid;
GO
In the exact same way, this procedure will wait to see whether any uncommitted rows it encounters will be rolled back or committed. No more missing rows for your ETL process!
When I deploy database changes, I like my scripts to be quick, non-blocking, rerunnable and resumable. I’ve discovered that:
Turning on Resource Governor is quick and online
Turning off Resource Governor is quick and online
Cleaning or removing configuration is easy
Modifying configuration may take some care
Turning on Resource Governor
Just like sp_configure, Resource Governor is configured in two steps. The first step is to specify the configuration you want, the second step is to ALTER RESOURCE GOVERNOR RECONFIGURE.
But unlike sp_configure which has a “config_value” column and a “run_value” column, there’s no single view that makes it easy to determine what values are configured, and what values are in use. It turns out that the catalog views are the configured values and the dynamic management views are the current values in use:
Catalog Views (configuration)
sys.resource_governor_configuration
sys.resource_governor_external_resource_pools
sys.resource_governor_resource_pools
sys.resource_governor_workload_groups
Dynamic Management Views (running values and stats)
sys.dm_resource_governor_configuration
sys.dm_resource_governor_external_resource_pools
sys.dm_resource_governor_resource_pools
sys.dm_resource_governor_workload_groups
When a reconfigure is pending, these views can contain different information and getting them straight is the key to writing rerunnable deployment scripts.
use master;
IFNOTEXISTS(SELECT*FROM sys.resource_governor_resource_poolsWHERE name ='SSMSPool')BEGINCREATE RESOURCE POOL SSMSPool;
ENDIFNOTEXISTS(SELECT*FROM sys.resource_governor_workload_groupsWHERE name ='SSMSGroup')BEGINCREATE WORKLOAD GROUP SSMSGroup
WITH(MAX_DOP =1)USING SSMSPool;
ENDIF(OBJECT_ID('dbo.resource_governor_classifier')ISNULL)BEGINDECLARE @SQLNVARCHAR(1000)= N'
CREATE FUNCTION dbo.resource_governor_classifier()
RETURNS sysname
WITH SCHEMABINDING
AS
BEGIN
RETURN
CASE APP_NAME()
WHEN ''Microsoft SQL Server Management Studio - Query'' THEN ''SSMSGroup''
ELSE ''default''
END;
END';
execsp_executesql @SQL;
END;
IFNOTEXISTS(SELECT*FROM sys.resource_governor_configuration/* config */WHERE classifier_function_id =OBJECT_ID('dbo.resource_governor_classifier'))ANDOBJECT_ID('dbo.resource_governor_classifier')ISNOTNULLBEGINALTER RESOURCE GOVERNOR WITH(CLASSIFIER_FUNCTION = dbo.resource_governor_classifier);
END
use master;
IF NOT EXISTS (
SELECT *
FROM sys.resource_governor_resource_pools
WHERE name = 'SSMSPool'
)
BEGIN
CREATE RESOURCE POOL SSMSPool;
END
IF NOT EXISTS (
SELECT *
FROM sys.resource_governor_workload_groups
WHERE name = 'SSMSGroup'
)
BEGIN
CREATE WORKLOAD GROUP SSMSGroup
WITH (MAX_DOP = 1)
USING SSMSPool;
END
IF ( OBJECT_ID('dbo.resource_governor_classifier') IS NULL )
BEGIN
DECLARE @SQL NVARCHAR(1000) = N'
CREATE FUNCTION dbo.resource_governor_classifier()
RETURNS sysname
WITH SCHEMABINDING
AS
BEGIN
RETURN
CASE APP_NAME()
WHEN ''Microsoft SQL Server Management Studio - Query'' THEN ''SSMSGroup''
ELSE ''default''
END;
END';
exec sp_executesql @SQL;
END;
IF NOT EXISTS (
SELECT *
FROM sys.resource_governor_configuration /* config */
WHERE classifier_function_id = OBJECT_ID('dbo.resource_governor_classifier') )
AND OBJECT_ID('dbo.resource_governor_classifier') IS NOT NULL
BEGIN
ALTER RESOURCE GOVERNOR WITH (CLASSIFIER_FUNCTION = dbo.resource_governor_classifier);
END
IFEXISTS(SELECT*FROM sys.dm_resource_governor_configurationWHERE is_reconfiguration_pending =1)OREXISTS(SELECT*FROM sys.resource_governor_configurationWHERE is_enabled =0)BEGINALTER RESOURCE GOVERNOR RECONFIGURE;
END
GO
IF EXISTS (
SELECT *
FROM sys.dm_resource_governor_configuration
WHERE is_reconfiguration_pending = 1
) OR EXISTS (
SELECT *
FROM sys.resource_governor_configuration
WHERE is_enabled = 0
)
BEGIN
ALTER RESOURCE GOVERNOR RECONFIGURE;
END
GO
Turning off Resource Governor
Pretty straightforward, the emergency stop button looks like this:
ALTER RESOURCE GOVERNOR DISABLE;
ALTER RESOURCE GOVERNOR DISABLE;
If you ever find yourself in big trouble (because you messed up the classifier function for example), use the Dedicated Admin Connection (DAC) to disable Resource Governor. The DAC uses the internal workload group regardless of how Resource Governor is configured.
After you’ve disabled Resource Governor, you may notice that the resource pools and workload groups are still sitting there. The configuration hasn’t been cleaned up or anything.
Cleaning Up
Cleaning up doesn’t start out too bad, deal with the classifier function, then drop the groups and pools:
ALTER RESOURCE GOVERNOR DISABLE
ALTER RESOURCE GOVERNOR WITH(CLASSIFIER_FUNCTION =NULL);
DROPFUNCTIONIFEXISTS dbo.resource_governor_classifier;
IFEXISTS(SELECT*FROM sys.resource_governor_workload_groupsWHERE name ='SSMSGroup')BEGINDROP WORKLOAD GROUP SSMSGroup;
ENDIFEXISTS(SELECT*FROM sys.resource_governor_resource_poolsWHERE name ='SSMSPool')BEGINDROP RESOURCE POOL SSMSPool;
END
ALTER RESOURCE GOVERNOR DISABLE
ALTER RESOURCE GOVERNOR WITH (CLASSIFIER_FUNCTION = NULL);
DROP FUNCTION IF EXISTS dbo.resource_governor_classifier;
IF EXISTS (
SELECT *
FROM sys.resource_governor_workload_groups
WHERE name = 'SSMSGroup'
)
BEGIN
DROP WORKLOAD GROUP SSMSGroup;
END
IF EXISTS (
SELECT *
FROM sys.resource_governor_resource_pools
WHERE name = 'SSMSPool'
)
BEGIN
DROP RESOURCE POOL SSMSPool;
END
You’ll be left in a state where is_reconfiguration_pending = 1 but since Resource Governor is disabled, it doesn’t really matter.
Modifying Resource Governor configuration
This is kind of a tricky thing and everyone’s situation is different. My advice would be to follow this kind of strategy:
Determine if the configuration is correct, if not:
Turn off Resource Governor
Clean up
Configure correctly (plot a course)
Turn on (make it so)
Somewhere along the way, if you delete a workload group that some session is still using, then ALTER RESOURCE GOVERNOR RECONFIGURE may give this error message:
Msg 10904, Level 16, State 2, Line 105
Resource governor configuration failed. There are active sessions in workload groups being dropped or moved to different resource pools.
Disconnect all active sessions in the affected workload groups and try again.
You have to wait for those sessions to end (or kill them) before trying again. But which sessions? These ones:
SELECT
dwg.name[currentworkgroup],
dwg.pool_id[current resource pool],
wg.name[configured workgroup],
wg.pool_id[configured resource pool],
s.*FROM
sys.dm_exec_sessions s
INNERJOIN
sys.dm_resource_governor_workload_groups dwg /* existing groups */ON dwg.group_id= s.group_idLEFTJOIN
sys.resource_governor_workload_groups wg /* configured groups */ON wg.group_id= s.group_idWHERE
isnull(wg.group_id, -1)<> dwg.pool_idORDERBY
s.session_id;
SELECT
dwg.name [current work group],
dwg.pool_id [current resource pool],
wg.name [configured work group],
wg.pool_id [configured resource pool],
s.*
FROM
sys.dm_exec_sessions s
INNER JOIN
sys.dm_resource_governor_workload_groups dwg /* existing groups */
ON dwg.group_id = s.group_id
LEFT JOIN
sys.resource_governor_workload_groups wg /* configured groups */
ON wg.group_id = s.group_id
WHERE
isnull(wg.group_id, -1) <> dwg.pool_id
ORDER BY
s.session_id;
If you find your own session in that list, reconnect.
Once that list is empty feel free to try again.
Yes, It turns out that you can specify two indexes in a table hint:
SELECT Id, Reputation
FROM dbo.UsersWITH(INDEX(IX_Reputation, PK_Users_Id))WHERE Reputation >1000
SELECT Id, Reputation
FROM dbo.Users WITH (INDEX (IX_Reputation, PK_Users_Id))
WHERE Reputation > 1000
And SQL Server obeys. It uses both indexes even though the nonclustered index IX_Reputation is covering:
But Why?
I think this is a solution looking for a problem.
Resolving Deadlocks?
My team wondered if this could be used as to help with a concurrency problem. We recently considered using it to resolve a particular deadlock but we had little success.
It’s useful to think that SQL Server takes locks on index rows instead of table rows. And so the idea we had was that perhaps taking key locks on multiple indexes can help control the order that locks are taken. But after some effort, it didn’t work at avoiding deadlocks. For me, I’ve had better luck using the simpler sp_getapplock.
Forcing Index Intersection?
Brent Ozar wrote about index intersection a while ago. Index intersection is a rare thing to find in a query plan. Brent can “count on one hand the number of times [he’s] seen this in the wild”.
In theory, I could force index intersection (despite the filter values):
SELECT Id
FROM dbo.UsersWITH(INDEX(IX_UpVotes, IX_Reputation))WHERE Reputation >500000AND UpVotes >500000
SELECT Id
FROM dbo.Users WITH (INDEX (IX_UpVotes, IX_Reputation))
WHERE Reputation > 500000
AND UpVotes > 500000
But I wouldn’t. SQL Server choosing index intersection is already so rare. And so I think the need to force that behavior will be even rarer. This is not a tool I would use for tuning queries. I’d leave this technique alone.
Have You Used More Than One Index Hint?
I’d love to hear about whether specifying more than one index in a table hint has ever helped solve a real world problem. Let me know in the comments.
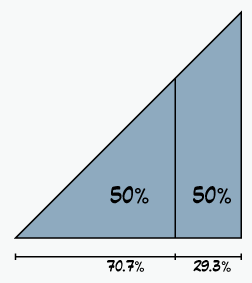
Using the right triangle above draw a vertical line separating the area of the triangle in to two parts with the same area.
The triangle on the left is 70.7% of the width of the original triangle.
Cumulative Storage Costs
Think of this another way. The triangle above is a graph of the amount of data you have over time. And if you pay for storage as an operational expense such as when you’re renting storage in the cloud (as opposed to purchasing physical drives). Then the cost of storage is the area of the graph. The monthly bills are ever-increasing, so half of the total cost of storage will be for the most recent 29%.
Put yet another way: If you started creating a large file in the cloud every day since March 2014, then the amount you paid to the cloud provider before the pandemic started is the same amount you paid after the pandemic started (as of August 2022).
How Sustainable is This?
If the amount of data generated a day isn’t that much, or the storage you’re using is cheap enough then it really doesn’t matter too much. As an example, AWS’s cheapest storage, S3 Glacier Deep Archive, works out to about $0.001 a month per GB.
But if you’re using Amazon’s Elastic Block Storage like the kind of storage needed for running your own SQL Servers in the cloud, the cost can be closer to $.08 a month per GB.
The scale on the triangle graph above really matters.
Strategies
This stresses the need for a data life-cycle policy. An exit story for large volumes of data. Try to implement Time-To-Live (TTL) or clean up mechanisms right from the beginning of even the smallest project. Here’s one quick easy example from a project I wrote that collects wait stats. The clean-up is a single line.
Look at Netflix does approaches this issue. I like how they put it. “Data storage has a lot of usage and cost momentum (i.e. save-and-forget build-up).”
Netflix stresses the importance of “cost visibility” and they use that to offer focused recommendations for cleaning up unused data. I recommend reading that whole article. It’s fascinating.
It’s important to implement such policies before that triangle graph gets too large.
Takeaway: I look at different features to see whether non-updates are treated the same as other updates. Most of the time they are.
According to Microsoft’s documentation, an UPDATE statement “changes existing data in a table or view”. But what if the values don’t actually change? What if affected rows are “updated” with the original values? Some call these updates non-updating. This leads to a philosophical question: “If an UPDATE statement doesn’t change any column to a different value, has the row been updated?”
I answer yes to that question. I consider all affected rows as “updated” regardless of whether the values are different. I think of the UPDATE statement as more of an OVERWRITE statement. I also think of “affected rows” rather than “changed rows”. In most cases SQL Server thinks along the same lines.
I list some features and areas of SQL Server and whether non-updating updates are treated the same or differently than other updates:
The Performance of Non-Updates Non-Updates treated differently than other Updates
In 2010, Paul White wrote The Impact of Non-Updating Updates where he points out optimizations Microsoft has made to avoid unnecessary logging when performing some non-updating updates. It’s a rare case where SQL Server actually does pay attention to whether values are not changing to avoid doing unnecessary work.
In the years since, I’ve noticed that this optimization hasn’t changed much except that Microsoft has extended these performance improvements to cases where RCSI or SI is enabled.
Regardless of this performance optimization, it’s still wise to limit affected rows as much as possible. In other words, I still prefer
UPDATE FactOnlineSales
SET DiscountAmount =NULLWHERE CustomerKey =19036AND DiscountAmount ISNOTNULL;
UPDATE FactOnlineSales
SET DiscountAmount = NULL
WHERE CustomerKey = 19036
AND DiscountAmount IS NOT NULL;
over this logically equivalent version:
UPDATE FactOnlineSales
SET DiscountAmount =NULLWHERE CustomerKey =19036;
UPDATE FactOnlineSales
SET DiscountAmount = NULL
WHERE CustomerKey = 19036;
Although the presence of triggers and cascading foreign keys require extra care as we’ll see.
Triggers Non-Updates are treated the same as Updates
Speaking of triggers, remember that inside a trigger, non-updating rows are treated exactly the same as any other changing row. Just remember that:
Triggers are always invoked, even when there are zero rows affected or even when the table is empty.
For UPDATE statements, the UPDATE() function only cares about whether a column appeared in the SET clause. It can be useful for short-circuit logic.
The virtual tables inserted and deleted are filled with all affected rows (not just changed rows).
ON UPDATE CASCADE Non-Updates are treated the same as Updates
When foreign keys have ON UPDATE CASCADE set, Microsoft says “corresponding rows are updated in the referencing table when that row is updated in the parent table”.
Non-updating updates are no exception. To demonstrate, I create an untrusted foreign key and perform a non-updating update. It’s not a “no-op”, the constraint is checked as expected.
CREATETABLE dbo.TestReferenced(
Id INTPRIMARYKEY);
INSERT dbo.TestReferenced(Id)VALUES(1), (2), (3), (4);
CREATETABLE dbo.TestReferrer(
Id INTNOTNULL);
INSERT dbo.TestReferrer(Id)VALUES(2), (4), (6), (8);
ALTERTABLE dbo.TestReferrerWITHNOCHECKADDFOREIGNKEY(Id)REFERENCES dbo.TestReferenced(Id)ONUPDATECASCADE;
-- trouble with this non-updating update:UPDATE dbo.TestReferrerSET Id = Id
WHERE Id =8;
-- The UPDATE statement conflicted with the FOREIGN KEY constraint ...
CREATE TABLE dbo.TestReferenced (
Id INT PRIMARY KEY
);
INSERT dbo.TestReferenced (Id) VALUES (1), (2), (3), (4);
CREATE TABLE dbo.TestReferrer (
Id INT NOT NULL
);
INSERT dbo.TestReferrer (Id) VALUES (2), (4), (6), (8);
ALTER TABLE dbo.TestReferrer
WITH NOCHECK ADD FOREIGN KEY (Id)
REFERENCES dbo.TestReferenced(Id)
ON UPDATE CASCADE;
-- trouble with this non-updating update:
UPDATE dbo.TestReferrer
SET Id = Id
WHERE Id = 8;
-- The UPDATE statement conflicted with the FOREIGN KEY constraint ...
@@ROWCOUNT Non-Updates are treated the same as Updates
SELECT @@ROWCOUNT returns the number of affected rows in the previous statement, not the number of changed rows.
Temporal Tables Non-Updates are treated the same as Updates
Non-updating updates still generate new rows in the history table. This can lead to puzzling results if you’re not prepared for them. For example, I can make some changes and query the history like this:
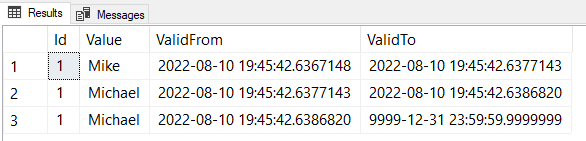
INSERT MyTest(Value) VALUES ('Mike')
UPDATE MyTest SET Value = 'Michael';
UPDATE MyTest SET Value = 'Michael';
When I take the union of rows in the table and the history table, I might see this output:
It reminds me of when my GPS says something like “In two miles, continue straight on Highway 81.” The value didn’t change, but there are still two distinct ranges.
Change Tracking Non-Updates are treated the same as Updates
Change tracking could be called “Overwrite Tracking” because all non-updating updates are tracked:
ALTERDATABASECURRENTset change_tracking =ON(change_retention =2 days, auto_cleanup =on);
GO
createtable dbo.test(id intprimarykey);
insert dbo.test(id)values(1), (2), (3);
altertable dbo.test enable change_tracking with(track_columns_updated =on)-- This statement produces 0 rows:SELECT t.id, c.*FROM CHANGETABLE (CHANGES dbo.Test, 0)AS c
JOIN dbo.TestAS t ON t.id= c.id ;
-- "update"update dbo.testset id = id;
-- This statement produces 3 rows:SELECT t.id, c.*FROM CHANGETABLE (CHANGES dbo.Test, 0)AS c
JOIN dbo.TestAS t ON t.id= c.id;
ALTER DATABASE CURRENT
set change_tracking = ON
(change_retention = 2 days, auto_cleanup = on);
GO
create table dbo.test (id int primary key);
insert dbo.test (id) values (1), (2), (3);
alter table dbo.test enable change_tracking with (track_columns_updated = on)
-- This statement produces 0 rows:
SELECT t.id, c.*
FROM CHANGETABLE (CHANGES dbo.Test, 0) AS c
JOIN dbo.Test AS t ON t.id = c.id ;
-- "update"
update dbo.test set id = id;
-- This statement produces 3 rows:
SELECT t.id, c.*
FROM CHANGETABLE (CHANGES dbo.Test, 0) AS c
JOIN dbo.Test AS t ON t.id = c.id;
Change Data Capture (CDC) Non-Updates treated differently than other Updates
Here’s a rare exception where a SQL Server feature is named properly. CDC does indeed capture data changes only when data is changing.
Paul White provided a handy set up for testing this kind of stuff. I reran his tests with CDC turned on. I found that:
When CDC is enabled, an update statement is always logged and the data buffers are always marked dirty.
But non-updating updates almost never show up as captured data changes, not even when the update was on a column in the clustering key.
I was able to generate some CDC changes for non-updates by updating the whole table with an idempotent expression (e.g. SET some_column = some column * 1)
CREATE TABLE dbo.SomeTable
(
some_column integer NOT NULL,
some_data integer NOT NULL,
index ix_sometable unique clustered (some_column)
);
UPDATE dbo.SomeTable SET some_column = some_column*1;
If you’re using this feature, this kind of stuff is important to understand! If you’re using CDC for DIY replication (God help you), then maybe the missing non-updates are acceptable. But if you’re looking for a kind of audit, or a way to analyze user-interactions with the database, then CDC doesn’t give the whole picture and is not the tool for you.
I want to describe some symptoms that SQL Server may display when its Windows Registry is non-responsive or slow. From the symptoms, it’s hard to know that it’s a slow registry and so if a web search brought you here, hopefully this helps.
How does SQL Server use the Windows registry?
First, it’s useful to know a bit about how SQL Server uses the registry. We can watch registry activity using Process Monitor (procmon). On a fairly quiet local machine, I see these SQL Server processes “querying” registry keys:
There is some background process reading Query Store settings (every minute). HKLM\Software\Microsoft\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQLServer\QueryStoreSettings
There is also some background process writing uptime info (every minute). HKLM\SOFTWARE\Microsoft\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQLServer\uptime_pid
When a login is requested from a new connection, SQL Server will check to see if R Services are installed (aka Advanced Analytics).
SQL Server will check SERVERPROPERTY('IsAdvancedAnalyticsInstalled') every time to see if it has to care about logins associated with something called implied authentication. This happens on every login which will be important later. HKLM\Software\Microsoft\Microsoft SQL Server\MSSQL15.MSSQLSERVER\Setup\AdvancedAnalytics
If I use a function like HASHBYTES, SQL Server looks up some cryptography settings. These settings get queried only on the first call to HASHBYTES in each session.
e.g. HKLM\SOFTWARE\Microsoft\Cryptography\Defaults\Provider\Microsoft Enhanced RSA and AES Cryptographic Provider
That’s not an exhaustive list, there are many other ways SQL Server uses the Windows Registry. For example:
Many SQL Agent settings are stored there and are read regularly
xp_regread coming from using wizards in SQL Server Management Studio.
SERVERPROPERTY(N'MachineName') gets its info from HKLM\System\CurrentControlSet\Services\Tcpip\Parameters\Hostname
And many others.
What happens when the Windows registry is slow?
SQL Server’s use of the registry can be fairly quiet – even on a busy server – so you may not see any symptoms at all. But if the calls to the registry are slow in responding, here is what you might see:
New logins will ask whether Advanced Analytics Extensions is installed. Leading to a non-yielding scheduler and a memory dump. With some effort, you might find a stack trace like the one in the appendix below.
Any other kind of memory dump caused by non-yielding schedulers in which the saved stack trace ends with ntdll!NtOpenKeyEx. The AdvancedAnalytics is just one example but it’s the most common because it’s executed first on each login.
Queries calling HASHBYTES (or other cryptography functions) will be suspended and wait with PREEMPTIVE_OS_CRYPTACQUIRECONTEXT. I mostly see this when the login checks are skipped i.e. when an open connection from a connection pool is used.
Another symptom is Availability Group failovers (allegedly). It’s harder (for me) to do AG failover post mortems and tie them definitively to slow Windows registries
Why might the registry be slow?
I’m not sure. Perhaps it’s associated with some registry cleanup process. It may have something to do with an IO spike on the C: drive.
We rebuilt a virtual machine image from scratch which seems to avoid the problem. I’m keeping my fingers crossed.
I’d love to hear if you’ve come across anything similar.
Appendix: Sample call stack for non-yielding scheduler