


How to deploy schema changes without scheduled downtime
In the first draft of this series, this post didn’t exist. I wanted to show a really simple example of a column switch and include it in the Blue-Green (Details) post. I planned for something simple. But I ran into some hiccups that I though were pretty instructive, so I turned it into the post you see here.
The Plan
For this demo, I wanted to use the WideWorldImporters database. In table Warehouse.ColdRoomTemperatures I wanted to change the column
ColdRoomSensorNumber INT NOT NULL,
into
ColdRoomSensorLabel NVARCHAR(100) NOT NULL,
because maybe we want to track sensors via some serial number or other code.
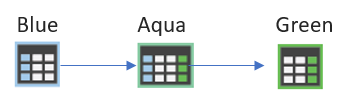
The Blue-Green plan would be simple:
The Trouble
But nothing is ever easy. Even SQL Server Data Tools (SSDT) gives up when I ask it to do this change with this error dialog:
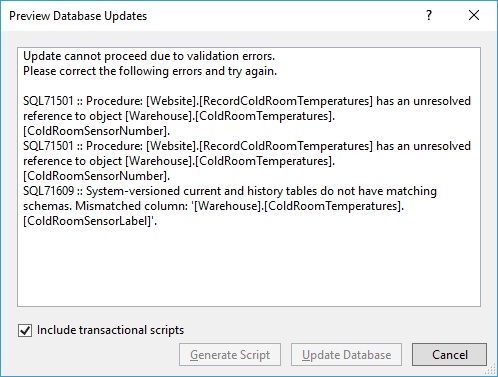
There’s two things going on here (and one hidden thing):
- The first two messages point out that a procedure is referencing the column
ColdRoomSensorNumberwith schemabinding. The reason it’s using schemabinding is because it’s a natively compiled stored procedure. And that tells me that the tableWarehouse.ColdRoomTemperaturesis an In-Memory table. That’s not all. I noticed another wrinkle. The procedure takes a table-valued parameter whose table type contains a column calledColdRoomSensorLabel. We’re going to have to replace that too. Ugh. Part of me wanted to look for another example. - The last message tells me that the table is a system versioned table. So there’s a corresponding archive table where history is maintained. That has to be dealt with too. Luckily Microsoft has a great article on Changing the Schema of a System-Versioned Temporal Table.
- One last thing to worry about is a index on
ColdRoomSensorNumber. That should be replaced with an index onColdRoomSensorLabel. SSDT didn’t warn me about that because apparently, it can deal with that pretty nicely.
So now my plan becomes:
Blue The original schema
Aqua After the pre-migration scripts are run

An extra step is required here to update the new column and keep the new and old columns in sync.
Green After the switch, we clean up the old objects and our schema change is finished:

Without further ado, here are the scripts:
Pre-Migration (Add Green Objects)
In the following scripts, I’ve omitted the IF EXISTS checks for clarity.
-- Add the four green objects ALTER TABLE Warehouse.ColdRoomTemperatures ADD ColdRoomSensorLabel NVARCHAR(100) NOT NULL CONSTRAINT DF_Warehouse_ColdRoomTemperatures_ColdRoomSensorLabel DEFAULT ''; GO ALTER TABLE Warehouse.ColdRoomTemperatures ADD INDEX IX_Warehouse_ColdRoomTemperatures_ColdRoomSensorLabel (ColdRoomSensorLabel); GO CREATE TYPE Website.SensorDataList_v2 AS TABLE( SensorDataListID int IDENTITY(1,1) NOT NULL, ColdRoomSensorLabel VARCHAR(100) NULL, RecordedWhen datetime2(7) NULL, Temperature decimal(18, 2) NULL, PRIMARY KEY NONCLUSTERED (SensorDataListID) ) GO CREATE PROCEDURE Website.RecordColdRoomTemperatures_v2 @SensorReadings Website.SensorDataList_v2 READONLY AS --straight-forward definition left as exercise for reader GO |
Pre-Migration (Populate and Keep in Sync)
Normally, I would use triggers to keep the new and old column values in sync like this, but you can’t do that with In-Memory tables. So I altered the procedure Website.RecordColdRoomTemperatures to achieve something similar. The only alteration I made is to set the ColdRoomSensorLabel value in the INSERT statement:
ALTER PROCEDURE Website.RecordColdRoomTemperatures @SensorReadings Website.SensorDataList READONLY WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER AS BEGIN ATOMIC WITH ( TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'English' ) BEGIN TRY DECLARE @NumberOfReadings int = (SELECT MAX(SensorDataListID) FROM @SensorReadings); DECLARE @Counter int = (SELECT MIN(SensorDataListID) FROM @SensorReadings); DECLARE @ColdRoomSensorNumber int; DECLARE @RecordedWhen datetime2(7); DECLARE @Temperature decimal(18,2); -- note that we cannot use a merge here because multiple readings might exist for each sensor WHILE @Counter <= @NumberOfReadings BEGIN SELECT @ColdRoomSensorNumber = ColdRoomSensorNumber, @RecordedWhen = RecordedWhen, @Temperature = Temperature FROM @SensorReadings WHERE SensorDataListID = @Counter; UPDATE Warehouse.ColdRoomTemperatures SET RecordedWhen = @RecordedWhen, Temperature = @Temperature WHERE ColdRoomSensorNumber = @ColdRoomSensorNumber; IF @@ROWCOUNT = 0 BEGIN INSERT Warehouse.ColdRoomTemperatures (ColdRoomSensorNumber, ColdRoomSensorLabel, RecordedWhen, Temperature) VALUES (@ColdRoomSensorNumber, 'HQ-' + CAST(@ColdRoomSensorNumber AS NVARCHAR(50)), @RecordedWhen, @Temperature); END; SET @Counter += 1; END; END TRY BEGIN CATCH THROW 51000, N'Unable to apply the sensor data', 2; RETURN 1; END CATCH; END; |
That keeps the values in sync for new rows. But now it’s time to update the values for existing rows. In my example, I imagine that the initial label for the sensors are initially: “HQ-1”, “HQ-2”, etc…
UPDATE Warehouse.ColdRoomTemperatures SET ColdRoomSensorLabel = 'HQ-' + CAST(ColdRoomSensorNumber as nvarchar(50)); |
Eagle-eyed readers will notice that I haven’t dealt with the history table here. If the history table is large use batching to update it. Or better yet, turn off system versioning and then turn it back on immediately using a new/empty history table (if feasible).
Post-Migration
After a successful switch, the green application is only calling Website.RecordColdRoomTemperatures_v2. It’s time now to clean up. Again, remember that order matters.
DROP PROCEDURE Website.RecordColdRoomTemperatures; DROP TYPE Website.SensorDataList; ALTER TABLE Warehouse.ColdRoomTemperatures DROP INDEX IX_Warehouse_ColdRoomTemperatures_ColdRoomSensorNumber; ALTER TABLE Warehouse.ColdRoomTemperatures DROP COLUMN ColdRoomSensorNumber; |

[…] Michael Swart amps up the complexity factor in his online deployment series: […]
Pingback by The Stage-And-Switch Technique For Deployments – Curated SQL — January 16, 2018 @ 8:06 am
Thank you for the great series! Linking to it will help me (and I believe a lot of other people) communicate on this important subject.
I chose to comment in this particular post because the SSDT error illustrates what might be an important planning consideration for people at the beginning of the database DevOps journey: do I use a state-based approach to migrations or a migration-based approach? With state-based approach, we declaratively describe the end state of the database and let the tools, usually with a bit of help from developer, figure out how to get us there. That’s the approach that tools like SSDT and Redgate tools other than ReadyRoll take. With state-based approach, state is explicit, migrations are implicit. In this series, there would be three states: blue, aqua, green. If we were using SSTD, we would have three revisions of the SSDT database project and we would do two deployments: one for the aqua revision and the other one for the green revision.
With migration-based approach, we define each migration by creating migration scripts, i.e. explicitly defining the path between neighboring states of the database. With migration-based approach, migrations are explicit, and have to be manually coded by a developer, and the state of the database is implicit. In this series, we would create two explicit migrations: blue -> aqua and aqua -> green. This is the approach that (I believe) this series implicitly used. There are some frameworks that help with migration-based approach (e.g. ReadyRoll mentioned above – not an endorsement, just an example), but usually such framework focus on the organization of migration scripts (e.g. some consistent naming convention), recording of migrations that have been completed in a database table and providing some runner for the migration scripts. The hard work of creating migration scripts must be done by a developer.
In my experience, a lot of teams choose state-based approach because it is nice to see full definitions of all database objects in source control and not have to worry about hand-crafting the migration scripts. They might also lack expertise to hand-craft complex online-friendly migration scripts.
Here, finally, comes the question: based on your experience, do you think that it is possible to use state-based approach to provide online migrations using tools like SSDT on non-trivial OLTP databases? Or if the current state of state-based migration tools is such that they won’t be able to do the job of generating online-friendly database migration scripts?
Thanks,
Sergei
Comment by Sergei Ryabkov — January 18, 2018 @ 6:46 am
This is an absolutely fantastic question Sergei. Thanks for asking it.
We use the migration-based approach like you mentioned. But surprisingly, our “source of truth” for what the definition should be is another set of create object scripts which are checked in separately. We do have the full definitions of all database objects in source control that you mentioned. And we use automated checks to avoid having our create-scripts diverge from migration-scripts.
During development, the check (Previous Clean Schema + Migration = Clean Schema) needs to pass before any changes can get merged into our main branch.
During deployment, we check that existing schema matches expected schema before the deployment process begins. We also have do a schema check for Green.
You did mention that there are two migrations here. Blue->Aqua and Aqua->Green. Although that’s true, our entire multi-step deployment process is so automated and coordinated that we usually think of it as two steps of a single migration. We don’t do a schema check for aqua.
So migration scripts becomes the responsibility of the developer. But the work is often easy to automate for simple cases. We make heavy use of a tool we wrote that can detect discrepancies between PreviousClean+Migration and Clean and suggest scripts. 90% of the time the suggested scripts are sufficient.
So to answer your question, I think it may be possible to use a state-based approach, because we do (in a way). But SSDT doesn’t help us too much except for the simplest changes. Our script suggestion tool we wrote helps us out much better. So I don’t think that any migration tool, can 100% always generate online-friendly schema changes. But there’s definitely opportunity for tools out there to be better than they are.
Comment by Michael J. Swart — January 18, 2018 @ 10:30 am
Hi Michael,
Let me return the compliment and say ‘What a fantastic answer!’ It sounds like you have found a way to combine the state-based and the migration-based approaches. I have not heard of anyone doing that, until now. I really like your script suggestion tool and the automated checks you use to make sure that the schema snapshots and the migration scripts are consistent.
If you don’t mind, I’d like to ask a clarifying question about your script suggestion tool. Did you write it from scratch or is it based on some kind of third-party SDK (e.g. Redgate SQL Compare SDK)?
Thank you,
Sergei
Comment by Sergei Ryabkov — January 19, 2018 @ 5:31 am
Hi Sergei,
That tool was written from scratch and I understand it was a lot of work. Using a third party SDK would have made the work easier, but because it’s meant to be used by every developer on their local machines, we wrote our own rather than use the kit. The scripts that are generated are just simple scripts, but they cover the majority of migration cases. Let’s say you have a database and have made some changes:
Which is easier said than done, especially for that last step. The thing that makes it easier, is that we make use of helper procedures (See the automation section in Blue Green Details)
Comment by Michael J. Swart — January 19, 2018 @ 8:40 am
Hi Michael,
Count me even more impressed, even if your script suggestion tool doesn’t handle all situations. Even Microsoft doesn’t seem to have developed SSDT from scratch: based on what I have heard, they licensed Redgate’s SQL Compare code in a one-time deal at some point, however I failed to find any proof of that transaction online.
Lack of good tools is one of the major factors that hinder SQL Server database CI/CD in my opinion. SSDT has limitations, Redgate DLM requires an almost $3,000 PER DEVELOPER license. Redgate’s SQL Compare SDK, which comes with a $800-dollar license for SQL Compare Pro allows you to distribute the app you create with the SDK up to 10 users (or machines) free of charge, but Redgate wants a fee for every additional machine/user after that. It might still be cheaper than developing things yourself from scratch, like you did. Sounds like it was expensive. By the way, I am not endorsing Redgate, even though I do like their tools, I just don’t know of any alternatives to SSDT and Redgate, assuming you want to be able to have the exact state of your database schema in source control (use state-based approach). As I said earlier, until yesterday, I haven’t heard of anybody combining the migration-based and the state-based approaches. I am pretty sure there are no commercial or open-source tools that do that. Maybe your company should consider selling the database tech you guys developed!
There is some hope that Microsoft is working on redoing SSDT right now: one can run SQL Server on Linux, the early versions of SQL Server Operations Studio, a cross-platform addition to (replacement for?) SSMS are out, but you still can’t run CI/CD for SQL Server on Linux, because SSDT is still Windows-only. Something has gotta be in the works. Maybe the new cross-platform SSDT will be better or, at least, open source. I guess we’ll see relatively soon.
Thank you again for your posts and for responding to my questions.
Best regards,
Sergei
Comment by Sergei Ryabkov — January 19, 2018 @ 11:52 am
Yes, lack of good tools is an issue. I would not consider our tool a great tool either. At least not for general consumption. But it works very well for our company. You wouldn’t believe the number of shortcuts we can take because our tool only needs to work for our company. For example, we don’t need to worry about things like assemblies, functions, linked servers or partitioned tables. We can ignore a huge number of object types that I haven’t mentioned because we simply don’t use them. 🙂
Comment by Michael J. Swart — January 19, 2018 @ 4:24 pm