


When I wrote Take Care When Scripting Batches, I wanted to guard against a common pitfall when implementing a batching solution (n-squared performance). I suggested a way to be careful. But I knew that my solution was not going to be universally applicable to everyone else’s situation. So I wrote that post with a focus on how to evaluate candidate solutions.
But we developers love recipes for problem solving. I wish it was the case that for whatever kind of problem you got, you just stick the right formula in and problem solved. But unfortunately everyone’s situation is different and the majority of questions I get are of the form “What about my situation?” I’m afraid that without extra details, the best advice remains to do the work to set up the tests and find out for yourself.

But despite that. I’m still going to answer some common questions I get. But I’m going to continue to focus on how I evaluate each solution.
(Before reading further, you might want to re-familiarize yourself with the original article Take Care When Scripting Batches).
Here are some questions I get:
What if the clustered index is not unique?
Or what if the clustered index had more than one column such that leading column was not unique. For example, imagine the table was created with this clustered primary key:
ALTER TABLE dbo.FactOnlineSales ADD CONSTRAINT PK_FactOnlineSales PRIMARY KEY CLUSTERED (DateKey, OnlineSalesKey) |
How do we write a batching script in that case? It’s usually okay if you just use the leading column of the clustered index. The careful batching script looks like this now:
DECLARE @LargestKeyProcessed DATETIME = '20000101', @NextBatchMax DATETIME, @RC INT = 1; WHILE (@RC > 0) BEGIN SELECT TOP (1000) @NextBatchMax = DateKey FROM dbo.FactOnlineSales WHERE DateKey > @LargestKeyProcessed AND CustomerKey = 19036 ORDER BY DateKey ASC; DELETE dbo.FactOnlineSales WHERE CustomerKey = 19036 AND DateKey > @LargestKeyProcessed AND DateKey <= @NextBatchMax; SET @RC = @@ROWCOUNT; SET @LargestKeyProcessed = @NextBatchMax; END |
The performance is definitely comparable to the original careful batching script:

Logical Reads Per Delete
But is it correct? A lot of people wonder if the non-unique index breaks the batching somehow. And the answer is yes, but it doesn’t matter too much.
By limiting the batches by DateKey instead of the unique OnlineSalesKey, we are giving up batches that are exactly 1000 rows each. In fact, most of the batches in my test process somewhere between 1000 and 1100 rows and the whole thing requires three fewer batches than the original script. That’s acceptable to me.
If I know that the leading column of the clustering key is selective enough to keep the batch sizes pretty close to the target size, then the script is still accomplishing its goal.
What if the rows I have to delete are sparse?
Here’s another situation. What if instead of customer 19036, we were asked to delete customer 7665? This time, instead of deleting 45100 rows, we only have to delete 379 rows.
I try the careful batching script and see that all rows are deleted in a single batch. SQL Server was looking for batches of 1000 rows to delete. But since there aren’t that many, it scanned the entire table to find just 379 rows. It completed in one batch, but that single batch performed as poorly as the straight algorithm.
One solution is to create an index (online!) for these rows. Something like:
CREATE INDEX IX_CustomerKey ON dbo.FactOnlineSales(CustomerKey) WITH (ONLINE = ON); |
Most batching scripts are one-time use. So maybe this index is one-time use as well. If it’s a temporary index, just remember to drop it after the script is complete. A temp table could also do the same trick.
With the index, the straight query only needed 3447 logical reads to find all the rows to delete:
DELETE dbo.FactOnlineSales WHERE CustomerKey = 7665; |

Logical Reads
Can I use the Naive algorithm if I use a new index?
How does the Naive and other algorithms fare with this new index on dbo.FactOnlineSales(CustomerKey)?
The rows are now so easy to find that the Naive algorithm no longer has the n-squared behavior we worried about earlier. But there is some extra overhead. We have to delete from more than one index. And we’re doing many b-tree lookups (instead of just scanning a clustered index).
Remember the Naive solution looks like this:
DECLARE @RC INT = 1; WHILE (@RC > 0) BEGIN DELETE TOP (1000) dbo.FactOnlineSales WHERE CustomerKey = 19036; SET @RC = @@ROWCOUNT END |
But now with the index, the performance looks like this (category Naive with Index)
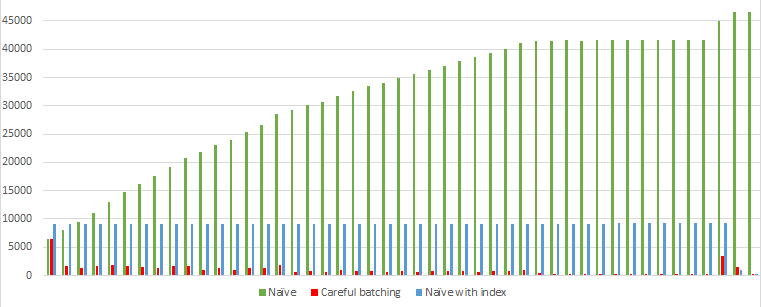
The index definitely helps. With the index, the Naive algorithm definitely looks better than it did without the index. But it still looks worse than the careful batching algorithm.
But look at that consistency! Each batch processes 1000 rows and reads exactly the same amount. I might choose to use Naive batching with an index if I don’t know how sparse the rows I’m deleting are. There are a lot of benefits to having a constant runtime for each batch when I can’t guarantee that rows aren’t sparse.
Explore new solutions on your own
There are many different solutions I haven’t explored. This list isn’t comprehensive.
But it’s all tradeoffs. When faced with a choice between candidate solutions, it’s essential to know how to test and measure each solution. SQL Server has more authoritative answers about the behavior of SQL Server than me or any one else. Good luck.

[…] Michael J. Swart follows up on an older post: […]
Pingback by Careful Batching – Curated SQL — September 22, 2022 @ 8:05 am