database table’s auto-incrementing ID column exceeded [maxint]. When we attempted to insert larger integers into the column, the database rejected the value
This led to a discussion about setting up monitoring for this kind of problem in our software. We have a place for monitoring and health-checks for all our databases. We just need to know how to define them.
So how do I create a script that reports any tables whose current identity values are above a certain threshold? This is what I came up with. Maybe you’ll find it useful too.
Find Tables in SQL Server Running Out Of Identity Room
declare @percentThreshold int=70;
select t.nameas[table],
c.nameas[column],
ty.nameas[type],
IDENT_CURRENT(t.name)as[identity],
100*IDENT_CURRENT(t.name)/2147483647as[percentfull]from sys.tables t
join sys.columns c
on c.object_id= t.object_idjoin sys.types ty
on ty.system_type_id= c.system_type_idwhere c.is_identity=1and ty.name='int'and100*IDENT_CURRENT(t.name)/2147483647> @percentThreshold
orderby t.name
declare @percentThreshold int = 70;
select t.name as [table],
c.name as [column],
ty.name as [type],
IDENT_CURRENT(t.name) as [identity],
100 * IDENT_CURRENT(t.name) / 2147483647 as [percent full]
from sys.tables t
join sys.columns c
on c.object_id = t.object_id
join sys.types ty
on ty.system_type_id = c.system_type_id
where c.is_identity = 1
and ty.name = 'int'
and 100 * IDENT_CURRENT(t.name) / 2147483647 > @percentThreshold
order by t.name
Other Notes
I really prefer sequences for this kind of thing. Monitoring goes along similar lines
I only worry about ints. Bigints are just too big.
I was looking at the docs for DROP TABLE and I noticed this in the syntax: [ ,...n ]. I never realized that you can drop more than one table in a statement.
You Still Have to Care About Order
I think that’s great. When dropping tables one at a time. You always had to be careful about order when foreign keys were involved. Alas, you still have to care about order. The docs say:
If both the referencing table and the table that holds the primary key are being dropped in the same DROP TABLE statement, the referencing table must be listed first.
That means that when you run
CREATETABLE A ( id INTPRIMARYKEY);
CREATETABLE B ( id INTFOREIGNKEYREFERENCES A(id));
DROPTABLEIFEXISTS A, B;
CREATE TABLE A ( id INT PRIMARY KEY );
CREATE TABLE B ( id INT FOREIGN KEY REFERENCES A(id) );
DROP TABLE IF EXISTS A, B;
It fails with
Msg 3726, Level 16, State 1, Line 4
Could not drop object ‘A’ because it is referenced by a FOREIGN KEY constraint.
This is a suggestion made by Matt Smith. Currently DROP TABLE behaves this way:
DROP TABLE IF EXISTS succeeds if the table exists and is deleted.
DROP TABLE IF EXISTS succeeds when there is no object with that name.
DROP TABLE IF EXISTS fails when that object name refers to an object that is not a table
For example, this script
CREATEVIEW C ASSELECT1AS One;
go
DROPTABLEIFEXISTS C;
CREATE VIEW C AS SELECT 1 AS One;
go
DROP TABLE IF EXISTS C;
gives the error
Msg 3705, Level 16, State 1, Line 9
Cannot use DROP TABLE with ‘C’ because ‘C’ is a view. Use DROP VIEW.
It’s really not in the spirit of what was intended with “IF EXISTS”. If you want to vote for that suggestion, it’s here DROP TABLE IF EXISTS fails
DROP TABLE is not Atomic
I’ve gotten really used to relying on atomic transactions. I know that when I update a set of rows, I can rely on the fact that all of the rows are updated, or in the case of an error, none of the rows are updated. There’s no situation where some of the rows are updated. But a DROP TABLE statement that tries to drop multiple tables using the [ ,...n ] syntax doesn’t behave that way. If there’s an error, SQL Server continues with the list dropping the tables that it can.
We can see that with the first example. Here it is again:
CREATETABLE A ( id INTPRIMARYKEY);
CREATETABLE B ( id INTFOREIGNKEYREFERENCES A(id));
DROPTABLEIFEXISTS A, B;
-- Could not drop object 'A' because it is referenced by a FOREIGN KEY constraint.-- B is dropped
CREATE TABLE A ( id INT PRIMARY KEY );
CREATE TABLE B ( id INT FOREIGN KEY REFERENCES A(id) );
DROP TABLE IF EXISTS A, B;
-- Could not drop object 'A' because it is referenced by a FOREIGN KEY constraint.
-- B is dropped
That example throws an error and drops a table.
The same nonatomic behavior is seen in a simpler example:
CREATETABLE D ( id INT);
DROPTABLE E, D;
-- Invalid object name 'E'-- D is dropped
CREATE TABLE D ( id INT );
DROP TABLE E, D;
-- Invalid object name 'E'
-- D is dropped
Solving real-world problems is different than answering interview questions or twitter polls. The biggest difference is that real problems aren’t always fair. There’s not always a right answer.
Answer this multiple choice question:
Which of the following SQL statements is used to modify existing data in a table?
A) SELECT
B) INSERT
C) DELETE
Give it some thought. Which option would you pick? The correct answer is UPDATE but it wasn’t one of the options listed and that’s not fair. But neither is real life. Many real problems don’t have an easy answer and some real problems are impossible to solve. That can be discouraging.
Real Problems Allow For Creativity
But if your problems are unfair, then maybe you’re allowed to cheat too.
“None of the above” is always an option. Understand the goal so that you can stretch or ignore requirements.
Example – Changing an INT to a BIGINT
I have a table that logs enrollments into courses. It’s append only and looks something like this:
CREATETABLE dbo.LOG_ENROLL(
LogId INTIDENTITYNOTNULL, -- This identity column is running out of space
UserId INTNOTNULL,
CourseId INTNOTNULL,
RoleId INTNULL,
EnrollmentType INTNOTNULL,
LogDate DATETIMENOTNULLDEFAULTGETUTCDATE(),
INDEX IX_LOG_ENROLL_CourseId CLUSTERED( CourseId, UserId ),
CONSTRAINT PK_LOG_ENROLL PRIMARYKEYNONCLUSTERED( LogId ),
INDEX IX_LOG_ENROLL_UserId NONCLUSTERED( UserId, CourseId ),
INDEX IX_LOG_ENROLL_LogDate NONCLUSTERED( LogDate, LogId ));
CREATE TABLE dbo.LOG_ENROLL (
LogId INT IDENTITY NOT NULL, -- This identity column is running out of space
UserId INT NOT NULL,
CourseId INT NOT NULL,
RoleId INT NULL,
EnrollmentType INT NOT NULL,
LogDate DATETIME NOT NULL DEFAULT GETUTCDATE(),
INDEX IX_LOG_ENROLL_CourseId CLUSTERED ( CourseId, UserId ),
CONSTRAINT PK_LOG_ENROLL PRIMARY KEY NONCLUSTERED ( LogId ),
INDEX IX_LOG_ENROLL_UserId NONCLUSTERED ( UserId, CourseId ),
INDEX IX_LOG_ENROLL_LogDate NONCLUSTERED ( LogDate, LogId )
);
The table has over 2 billion rows and it looks like it’s going to run out of space soon because the LogId column is defined as an INT. I need to change this table so that it’s a BIGINT. But changing an INT to a BIGINT is known as a “size of data” operation. This means SQL Server has to process every row to expand the LogId column from 4 to 8 bytes. But it gets trickier than that.
The biggest challenge is that the table has to remain “online” (available for queries and inserts).
Compression?
Gianluca Sartori (spaghettidba) had the idea of enlarging the columns with no downtime using compression. It’s promising, but I discovered that for this to work, all indexes need to be compressed not just the ones that contain the changed column. Also, any indexes which use the column need to be disabled for this to work.
Cheating
I gave up on solving this problem in general and constrained my focus to the specific problem I was facing. There’s always some context that lets us bend the rules. In my case, here’s what I did.
Ahead of time:
I removed extra rows. I discovered that many of the rows were extraneous and could be removed. After thinning out the table, the number of rows went from 2 billion down to 300 million.
I compressed two of the indexes online (IX_LOG_ENROLL_UserId and IX_LOG_ENROLL_CourseId) because I still want to use the compression trick.
But I’m not ready yet. I still can’t modify the column because the other two indexes depend on the LogId column. If I tried, I get this error message:
Msg 5074, Level 16, State 1, Line 22
The index ‘IX_LOG_ENROLL_LogDate’ is dependent on column ‘LogId’.
Msg 5074, Level 16, State 1, Line 22
The object ‘PK_LOG_ENROLL’ is dependent on column ‘LogId’.
Msg 4922, Level 16, State 9, Line 22
ALTER TABLE ALTER COLUMN LogId failed because one or more objects access this column.
So I temporarily drop those indexes!
Drop the constraint PK_LOG_ENROLL and the index IX_LOG_ENROLL_LogDate
Do the switch! ALTER TABLE LOG_ENROLL ALTER COLUMN LogId BIGINT NOT NULL; This step takes no time!
Recreate the indexes online that were dropped.
Hang on, that last step is a size of data operation. Anyone who needs those indexes won’t be able to use them while they’re being built.
Exactly, and this is where I cheat. It turns out those indexes were used for infrequent reports and I was able to co-ordinate my index rebuild around the reporting schedule.
You can’t always make an operation online, but with effort and creativity, you can get close enough. I have found that every real problem allows for a great degree of creativity when you’re allowed to bend the rules or question requirements.
The transaction is touching two different databases. So it makes sense that the two actions should be atomic and durable together using the one single transaction.
However, databases implement durability and atomicity using their own transaction log. Each transaction log takes care of its own database. So from another point of view, it makes sense that these are two separate transactions.
A transaction within a single instance of the Database Engine that spans two or more databases is actually a distributed transaction. The instance manages the distributed transaction internally; to the user, it operates as a local transaction.
I can actually see that happening with this demo script:
use master
ifexists(select*from sys.databaseswhere name ='D1')beginalterdatabase D1 set single_user withrollbackimmediate;
dropdatabase D1;
end
go
ifexists(select*from sys.databaseswhere name ='D2')beginalterdatabase D2 set single_user withrollbackimmediate;
dropdatabase D2;
end
go
createdatabase d1;
go
createdatabase d2;
go
createtable d1.dbo.T1(id int);
createtable d2.dbo.T1(id int);
go
use d1;
CHECKPOINT;
go
begintransactioninsert d1.dbo.T1values(1);
insert d2.dbo.T1values(1);
commitselect[Transaction ID], [Transaction Name], Operation, Context, [Description]from fn_dblog(null, null);
use master
if exists (select * from sys.databases where name = 'D1')
begin
alter database D1 set single_user with rollback immediate;
drop database D1;
end
go
if exists (select * from sys.databases where name = 'D2')
begin
alter database D2 set single_user with rollback immediate;
drop database D2;
end
go
create database d1;
go
create database d2;
go
create table d1.dbo.T1 (id int);
create table d2.dbo.T1 (id int);
go
use d1;
CHECKPOINT;
go
begin transaction
insert d1.dbo.T1 values (1);
insert d2.dbo.T1 values (1);
commit
select [Transaction ID], [Transaction Name], Operation, Context, [Description]
from fn_dblog(null, null);
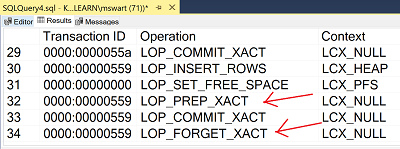
That shows a piece of what’s going on in the transaction log like this:
If you’re familiar with fn_dblog output (or even if you’re not), notice that when a transaction touches two databases, there are extra entries in the transaction log. D1 has LOP_PREP_XACT and LOP_FORGET_XACT and D2 only has LOP_PREP_XACT. Grahaeme Ross wrote a lot more about what this means in his article Understanding Cross-Database Transactions in SQL Server
Well that’s good. I can count on that can’t I?
Except When …
You Break Atomicity On Purpose
Well, they are two databases after all. If you want to restore one database to a point in time before the transaction occurred but not the other, I’m not going to stop you.
Availability Groups
But there’s another wrench to throw in with Availability Groups. Again Microsoft’s docs are pretty clear on this (Thanks Brent for pointing me to them). In Transactions – availability groups and database mirroring they point out this kind of thing is pretty new:
In SQL Server 2016 SP1 and before, cross-database transactions within the same SQL Server instance are not supported for availability groups.
There’s support in newer versions, but the availability group had to have been created with WITH DTC_SUPPORT = PER_DB. There’s no altering the availability group after it’s been created.
It’s also interesting that availability groups’ older brother, database mirroring is absolutely not supported. Microsoft says so several times and wants you to know that if you try and you mess up, it’s on you:
… any issues arising from the improper use of distributed transactions are not supported.
Long story short:
Cross DB Transactions in the same server are supported with Availability Groups in SQL Server 2017 and later
Cross DB Transactions are not supported with mirrored databases at all
After identifying a database you’re curious about, you may want to drill down further. I wrote about this problem earlier in Tackle WRITELOG Waits Using the Transaction Log and Extended Events. The query I wrote for that post combines results of an extended events session with the transaction log in order to identify which procedures are doing the most writing.
But it’s a tricky kind of script. It takes a while to run on busy systems. There’s a faster way to drill into writes if you switch your focus from which queries are writing so much to which tables are being written to so much. Both methods of drilling down can be helpful, but the table approach is faster and doesn’t require an extended event session and it might be enough to point you in the right direction.
Use This Query
use[specify your databasename here]-- get the latest lsn for current DBdeclare @xact_seqno binary(10);
declare @xact_seqno_string_begin varchar(50);
exec sp_replincrementlsn @xact_seqno OUTPUT;
set @xact_seqno_string_begin ='0x'+CONVERT(varchar(50), @xact_seqno, 2);
set @xact_seqno_string_begin =stuff(@xact_seqno_string_begin, 11, 0, ':')set @xact_seqno_string_begin =stuff(@xact_seqno_string_begin, 20, 0, ':');
-- wait a few secondswaitfor delay '00:00:10'-- get the latest lsn for current DBdeclare @xact_seqno_string_end varchar(50);
exec sp_replincrementlsn @xact_seqno OUTPUT;
set @xact_seqno_string_end ='0x'+CONVERT(varchar(50), @xact_seqno, 2);
set @xact_seqno_string_end =stuff(@xact_seqno_string_end, 11, 0, ':')set @xact_seqno_string_end =stuff(@xact_seqno_string_end, 20, 0, ':');
WITH[Log]AS(SELECT Category,
SUM([Log Record Length])as[Log Bytes]FROM fn_dblog(@xact_seqno_string_begin, @xact_seqno_string_end)CROSS APPLY (SELECT ISNULL(AllocUnitName, Operation))AS C(Category)GROUPBY Category
)SELECT Category,
[Log Bytes],
100.0*[Log Bytes]/SUM([Log Bytes])OVER()AS[%]FROM[Log]ORDERBY[Log Bytes]DESC;
use [specify your databasename here]
-- get the latest lsn for current DB
declare @xact_seqno binary(10);
declare @xact_seqno_string_begin varchar(50);
exec sp_replincrementlsn @xact_seqno OUTPUT;
set @xact_seqno_string_begin = '0x' + CONVERT(varchar(50), @xact_seqno, 2);
set @xact_seqno_string_begin = stuff(@xact_seqno_string_begin, 11, 0, ':')
set @xact_seqno_string_begin = stuff(@xact_seqno_string_begin, 20, 0, ':');
-- wait a few seconds
waitfor delay '00:00:10'
-- get the latest lsn for current DB
declare @xact_seqno_string_end varchar(50);
exec sp_replincrementlsn @xact_seqno OUTPUT;
set @xact_seqno_string_end = '0x' + CONVERT(varchar(50), @xact_seqno, 2);
set @xact_seqno_string_end = stuff(@xact_seqno_string_end, 11, 0, ':')
set @xact_seqno_string_end = stuff(@xact_seqno_string_end, 20, 0, ':');
WITH [Log] AS
(
SELECT Category,
SUM([Log Record Length]) as [Log Bytes]
FROM fn_dblog(@xact_seqno_string_begin, @xact_seqno_string_end)
CROSS APPLY (SELECT ISNULL(AllocUnitName, Operation)) AS C(Category)
GROUP BY Category
)
SELECT Category,
[Log Bytes],
100.0 * [Log Bytes] / SUM([Log Bytes]) OVER () AS [%]
FROM [Log]
ORDER BY [Log Bytes] DESC;
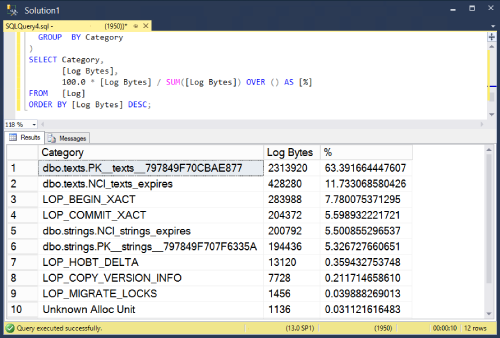
Results look something like this (Your mileage may vary).
Notes
Notice that some space in the transaction log is not actually about writing to tables. I’ve grouped them into their own categories and kept them in the results. For example LOP_BEGIN_XACT records information about the beginning of transactions.
I’m using sp_replincrementlsn to find the current last lsn. I could have used log_min_lsn from sys.dm_db_log_stats but that dmv is only available in 2016 SP2 and later.
This method is a little more direct measurement of transaction log activity than a similar query that uses sys.dm_db_index_operational_stats
Taking a small break from my blogging sabbatical to post one script that I’ve found myself writing from scratch too often.
My hope is that the next time I need this, I’ll look it up here.
The User Settable Counter
Use this to monitor something that’s not already exposed as a performance counter. Like the progress of a custom task or whatever. If you can write a quick query, you can expose it to a counter that can be plotted by Performance Monitor.
Here’s the script (adjust SomeMeasurement and SomeTable to whatever makes sense and adjust the delay interval if 1 second is too short:
declare @deltaMeasurement int = 0;
declare @totalMeasurement int = 0;
while (1=1)
begin
select @deltaMeasurement = SomeMeasurement - @totalMeasurement
from SomeTable;
set @totalMeasurement += @deltaMeasurement;
exec sp_user_counter1 @deltaMeasurement;
waitfor delay '00:00:01'
end
Monitoring
Now you can monitor “User Counter 1” in the object “SQLServer:User Settable” which will look like this:
Don’t forget to stop the running query when you’re done.
A couple weeks ago, I wrote about how to find lonely tables in Sql Server. This is a follow up to that post. I’m now going to talk about small sets of tables that are joined to eachother, but no-one else.
It’s Not Just Me
It seems everyone’s talking about this.
So as I was writing this post and code I noticed an amazing coincidence. I saw the same ideas I was writing about being discussed on twitter by Kelly Sommers, Ben Johnson and others.
They discuss Uber’s microservice graph. When visualized, it’s a big mish-mash of dependencies. Kelly points out how hard it is to reason about and Ben points to a small decoupled piece of the system that he wants to work on.
Me too Ben! And I think that’s the value of that visualization. It can demonstrate to others how tangled your system is. It can also identify small components that are not connected to the main mess. When I tie it to my last post and consider this idea in the database world, I can expand my idea of lonely tables to small sets of tables that are never joined to other tables.
I want to find them because these tables are also good candidates for extraction but how do I find them? I start by visualizing tables and their joins.
Visualizing Table Joins
I started by looking for existing visualizations. I didn’t find exactly what I wanted so I coded my own visualization (with the help of the d3 library). It’s always fun to code your own physics engine.
Here’s what I found
A monolith with some smaller isolated satellites
An example that might be good to extract
That ball of mush in the middle is hard to look at, but the smaller disconnected bits aren’t! Just like Ben, I want to work on those smaller pieces too! And just like the lonely tables we looked at last week, these small isolated components are also good candidates for extracting from SQL Server.
There’s a query at the end of this post. When you run it, you’ll get pairs of table names and when you paste it into the Show Graph page, you’ll see a visualization of your database.
(This is all client-side code, I don’t collect any data).
The Query
use[your database name goes here];
select
qs.query_hash,
qs.plan_handle,
cast(nullas xml)as query_plan
into #myplans
from sys.dm_exec_query_stats qs
cross apply sys.dm_exec_plan_attributes(qs.plan_handle) pa
where pa.attribute='dbid'and pa.value=db_id();
with duplicate_queries as(select ROW_NUMBER()over(partition by query_hash orderby(select1)) r
from #myplans
)delete duplicate_queries
where r >1;
update #myplans
set query_plan = qp.query_planfrom #myplans mp
cross apply sys.dm_exec_query_plan(mp.plan_handle) qp
;WITH XMLNAMESPACES (DEFAULT'http://schemas.microsoft.com/sqlserver/2004/07/showplan'),
mycte as(select q.query_hash,
obj.value('(@Schema)[1]', 'sysname')AS schema_name,
obj.value('(@Table)[1]', 'sysname')AS table_name
from #myplans q
cross apply q.query_plan.nodes('/ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple')as nodes(stmt)CROSS APPLY stmt.nodes('.//IndexScan/Object')AS index_object(obj))select query_hash, schema_name, table_name
into #myExecutions
from mycte
where schema_name isnotnullandobject_id(schema_name +'.'+ table_name)in(selectobject_idfrom sys.tables)groupby query_hash, schema_name, table_name;
selectDISTINCT A.table_nameas first_table,
B.table_nameas second_table
from #myExecutions A
join #myExecutions B
on A.query_hash= B.query_hashwhere A.table_name< B.table_name;
use [your database name goes here];
select
qs.query_hash,
qs.plan_handle,
cast(null as xml) as query_plan
into #myplans
from sys.dm_exec_query_stats qs
cross apply sys.dm_exec_plan_attributes(qs.plan_handle) pa
where pa.attribute = 'dbid'
and pa.value = db_id();
with duplicate_queries as
(
select ROW_NUMBER() over (partition by query_hash order by (select 1)) r
from #myplans
)
delete duplicate_queries
where r > 1;
update #myplans
set query_plan = qp.query_plan
from #myplans mp
cross apply sys.dm_exec_query_plan(mp.plan_handle) qp
;WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan'),
mycte as
(
select q.query_hash,
obj.value('(@Schema)[1]', 'sysname') AS schema_name,
obj.value('(@Table)[1]', 'sysname') AS table_name
from #myplans q
cross apply q.query_plan.nodes('/ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple') as nodes(stmt)
CROSS APPLY stmt.nodes('.//IndexScan/Object') AS index_object(obj)
)
select query_hash, schema_name, table_name
into #myExecutions
from mycte
where schema_name is not null
and object_id(schema_name + '.' + table_name) in (select object_id from sys.tables)
group by query_hash, schema_name, table_name;
select DISTINCT A.table_name as first_table,
B.table_name as second_table
from #myExecutions A
join #myExecutions B
on A.query_hash = B.query_hash
where A.table_name < B.table_name;
Takeaway: I provide a script that looks at the procedure cache and reports tables that are never joined to other tables.
Recently, I’ve been working hard to reduce our use of SQL Server as much as possible. In other words, I’ve been doing some spring cleaning. I pick up a table in my hands and I look at it. If it doesn’t spark joy then I drop it.
If only it were that easy. That’s not quite the process I’m using. The specific goals I’m chasing are about reducing cost. I’m moving data to cheaper data stores when it makes sense.
So let’s get tidying. But where do I start?
Getting rid of SQL Server tables should accomplish a couple things. First, it should “move the needle”. If my goal is cost, then the tables I choose to remove should reduce my hardware or licensing costs in a tangible way. The second thing is that dropping the table is achievable without 10 years of effort. So I want to focus on “achievability” for a bit.
Achievable
What’s achievable? I want to identify tables to extract from the database that won’t take years. Large monolithic systems can have a lot of dependencies to unravel.
So what tables in the database have the least dependencies? How do I tell without a trustworthy data model? Is it the ones with the fewest foreign keys (in or out)? Maybe, but foreign keys aren’t always defined properly or they can be missing all together.
My thought is that if two tables are joined together in some query, then they’re related or connected in some fashion. So that’s my idea. I can look at the procedure cache of a database in production to see where the connections are. And when I know that, I can figure out what tables are not connected.
Lonely Tables
This script gives me set of tables that aren’t joined to any other table in any query in cache
use[your db name here];
SELECT qs.query_hash,
qs.plan_handle,
cast(nullas xml)as query_plan
INTO #myplans
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_plan_attributes(qs.plan_handle) pa
WHERE pa.attribute='dbid'AND pa.value=db_id();
WITH duplicate_queries AS(SELECT ROW_NUMBER()OVER(PARTITION BY query_hash ORDERBY(SELECT1)) n
FROM #myplans
)DELETE duplicate_queries
WHERE n >1;
UPDATE #myplans
SET query_plan = qp.query_planFROM #myplans mp
CROSS APPLY sys.dm_exec_query_plan(mp.plan_handle) qp;
WITH XMLNAMESPACES (DEFAULT'http://schemas.microsoft.com/sqlserver/2004/07/showplan'),
my_cte AS(SELECT q.query_hash,
obj.value('(@Schema)[1]', 'sysname')AS[schema_name],
obj.value('(@Table)[1]', 'sysname')AS table_name
FROM #myplans q
CROSS APPLY q.query_plan.nodes('/ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple')as nodes(stmt)CROSS APPLY stmt.nodes('.//IndexScan/Object')AS index_object(obj))SELECT query_hash, [schema_name], table_name
INTO #myExecutions
FROM my_cte
WHERE[schema_name]ISNOTNULLANDOBJECT_ID([schema_name]+'.'+ table_name)IN(SELECTobject_idFROM sys.tables)GROUPBY query_hash, [schema_name], table_name;
WITH multi_table_queries AS(SELECT query_hash
FROM #myExecutions
GROUPBY query_hash
HAVINGCOUNT(*)>1),
lonely_tables as(SELECT[schema_name], table_name
FROM #myExecutions
EXCEPTSELECT[schema_name], table_name
FROM #myexecutions WHERE query_hash IN(SELECT query_hash FROM multi_table_queries))SELECT l.*, ps.row_countFROM lonely_tables l
JOIN sys.dm_db_partition_stats ps
ONOBJECT_ID(l.[schema_name]+'.'+ l.table_name)= ps.object_idWHERE ps.index_idin(0,1)ORDERBY ps.row_countDESC;
use [your db name here];
SELECT qs.query_hash,
qs.plan_handle,
cast(null as xml) as query_plan
INTO #myplans
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_plan_attributes(qs.plan_handle) pa
WHERE pa.attribute = 'dbid'
AND pa.value = db_id();
WITH duplicate_queries AS
(
SELECT ROW_NUMBER() OVER (PARTITION BY query_hash ORDER BY (SELECT 1)) n
FROM #myplans
)
DELETE duplicate_queries
WHERE n > 1;
UPDATE #myplans
SET query_plan = qp.query_plan
FROM #myplans mp
CROSS APPLY sys.dm_exec_query_plan(mp.plan_handle) qp;
WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan'),
my_cte AS
(
SELECT q.query_hash,
obj.value('(@Schema)[1]', 'sysname') AS [schema_name],
obj.value('(@Table)[1]', 'sysname') AS table_name
FROM #myplans q
CROSS APPLY q.query_plan.nodes('/ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple') as nodes(stmt)
CROSS APPLY stmt.nodes('.//IndexScan/Object') AS index_object(obj)
)
SELECT query_hash, [schema_name], table_name
INTO #myExecutions
FROM my_cte
WHERE [schema_name] IS NOT NULL
AND OBJECT_ID([schema_name] + '.' + table_name) IN (SELECT object_id FROM sys.tables)
GROUP BY query_hash, [schema_name], table_name;
WITH multi_table_queries AS
(
SELECT query_hash
FROM #myExecutions
GROUP BY query_hash
HAVING COUNT(*) > 1
),
lonely_tables as
(
SELECT [schema_name], table_name
FROM #myExecutions
EXCEPT
SELECT [schema_name], table_name
FROM #myexecutions WHERE query_hash IN (SELECT query_hash FROM multi_table_queries)
)
SELECT l.*, ps.row_count
FROM lonely_tables l
JOIN sys.dm_db_partition_stats ps
ON OBJECT_ID(l.[schema_name] + '.' + l.table_name) = ps.object_id
WHERE ps.index_id in (0,1)
ORDER BY ps.row_count DESC;
Caveats
So many caveats.
There are so many things that take away from the accuracy and utility of this script that I hesitated to even publish it.
Here’s the way I used the script. The list of tables was something that helped me begin an investigation. For me, I didn’t use it to give answers, but to generate questions. For example, taking each table in the list, I asked: “How hard would it be to get rid of table X and what would that save us?” I found it useful to consider those questions. Your mileage of course will vary.
The other day, Erin Stellato asked a question on twitter about the value of nested SPs. Here’s how I weighed in:
I’m not a fan of nested anything. Too much hidden complexity. Code reusability leads to queries that are jack of all trades, master of none. “Don’t repeat yourself” doesn’t work as well in SQL as it does in other code.
Hidden complexity has given me many problems in the past. SQL Server really really likes things simple and so it’s nice to be able to uncover that complexity. Andy Yun has tackled this problem for nested views with his sp_helpexpandview.
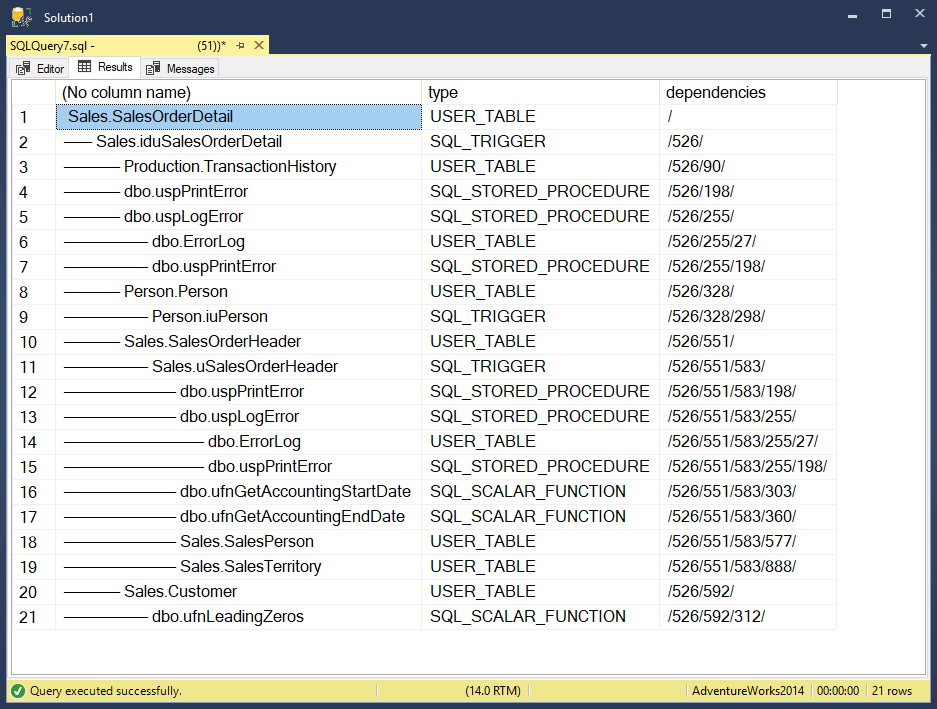
Here’s what I came up with for nested anything. It helps unravel a tree of dependencies based on information found in sys.triggers and sys.dm_sql_referenced_entities. With it, you can see what’s involved when interacting with objects. Here’s what things look like for Sales.SalesOrderDetail in AdventureWorks2014. A lot of the resulting rows can be ignored, but there can be surprises in there too.
DECLARE @object_name SYSNAME ='Sales.SalesOrderDetail';
WITH dependencies AS(SELECT @object_nameAS[object_name],
CAST(QUOTENAME(OBJECT_SCHEMA_NAME(OBJECT_ID(@object_name)))+'.'+QUOTENAME(OBJECT_NAME(OBJECT_ID(@object_name)))as sysname)as[escaped_name],
[type_desc],
object_id(@object_name)AS[object_id],
1AS is_updated,
CAST('/'+CAST(object_id(@object_name)%10000asVARCHAR(30))+'/'AS hierarchyid)as tree,
0as trigger_parent_id
FROM sys.objectsWHEREobject_id=object_id(@object_name)UNIONALLSELECTCAST(OBJECT_SCHEMA_NAME(o.[object_id])+'.'+OBJECT_NAME(o.[object_id])as sysname),
CAST(QUOTENAME(OBJECT_SCHEMA_NAME(o.[object_id]))+'.'+QUOTENAME(OBJECT_NAME(o.[object_id]))as sysname),
o.[type_desc],
o.[object_id],
CASE o.[type]when'U'then re.is_updatedelse1end,
CAST(d.tree.ToString()+CAST(o.[object_id]%10000asVARCHAR(30))+'/'AS hierarchyid),
0as trigger_parent_id
FROM dependencies d
CROSS APPLY sys.dm_sql_referenced_entities(d.[escaped_name], default) re
JOIN sys.objects o
ON o.object_id= isnull(re.referenced_id, object_id(ISNULL(re.referenced_schema_name,'dbo')+'.'+ re.referenced_entity_name))WHERE tree.GetLevel()<10AND re.referenced_minor_id=0AND o.[object_id]<> d.trigger_parent_idANDCAST(d.tree.ToString()asvarchar(1000))notlike'%'+CAST(o.[object_id]%10000asvarchar(1000))+'%'UNIONALLSELECTCAST(OBJECT_SCHEMA_NAME(t.[object_id])+'.'+OBJECT_NAME(t.[object_id])as sysname),
CAST(QUOTENAME(OBJECT_SCHEMA_NAME(t.[object_id]))+'.'+QUOTENAME(OBJECT_NAME(t.[object_id]))as sysname),
'SQL_TRIGGER',
t.[object_id],
0AS is_updated,
CAST(d.tree.ToString()+CAST(t.object_id%10000asVARCHAR(30))+'/'AS hierarchyid),
t.parent_idas trigger_parent_id
FROM dependencies d
JOIN sys.triggers t
ON d.[object_id]= t.parent_idWHERE d.is_updated=1AND tree.GetLevel()<10ANDCAST(d.tree.ToString()asvarchar(1000))notlike'%'+cast(t.[object_id]%10000asvarchar(1000))+'%')SELECTreplicate('—', tree.GetLevel()-1)+' '+[object_name],
[type_desc]as[type],
tree.ToString()as dependencies
FROM dependencies
ORDERBY tree
DECLARE @object_name SYSNAME = 'Sales.SalesOrderDetail';
WITH dependencies AS
(
SELECT @object_name AS [object_name],
CAST(
QUOTENAME(OBJECT_SCHEMA_NAME(OBJECT_ID(@object_name))) + '.' +
QUOTENAME(OBJECT_NAME(OBJECT_ID(@object_name)))
as sysname) as [escaped_name],
[type_desc],
object_id(@object_name) AS [object_id],
1 AS is_updated,
CAST('/' + CAST(object_id(@object_name) % 10000 as VARCHAR(30)) + '/' AS hierarchyid) as tree,
0 as trigger_parent_id
FROM sys.objects
WHERE object_id = object_id(@object_name)
UNION ALL
SELECT CAST(OBJECT_SCHEMA_NAME(o.[object_id]) + '.' + OBJECT_NAME(o.[object_id]) as sysname),
CAST(QUOTENAME(OBJECT_SCHEMA_NAME(o.[object_id])) + '.' + QUOTENAME(OBJECT_NAME(o.[object_id])) as sysname),
o.[type_desc],
o.[object_id],
CASE o.[type] when 'U' then re.is_updated else 1 end,
CAST(d.tree.ToString() + CAST(o.[object_id] % 10000 as VARCHAR(30)) + '/' AS hierarchyid),
0 as trigger_parent_id
FROM dependencies d
CROSS APPLY sys.dm_sql_referenced_entities(d.[escaped_name], default) re
JOIN sys.objects o
ON o.object_id = isnull(re.referenced_id, object_id(ISNULL(re.referenced_schema_name,'dbo') + '.' + re.referenced_entity_name))
WHERE tree.GetLevel() < 10
AND re.referenced_minor_id = 0
AND o.[object_id] <> d.trigger_parent_id
AND CAST(d.tree.ToString() as varchar(1000)) not like '%' + CAST(o.[object_id] % 10000 as varchar(1000)) + '%'
UNION ALL
SELECT CAST(OBJECT_SCHEMA_NAME(t.[object_id]) + '.' + OBJECT_NAME(t.[object_id]) as sysname),
CAST(QUOTENAME(OBJECT_SCHEMA_NAME(t.[object_id])) + '.' + QUOTENAME(OBJECT_NAME(t.[object_id])) as sysname),
'SQL_TRIGGER',
t.[object_id],
0 AS is_updated,
CAST(d.tree.ToString() + CAST(t.object_id % 10000 as VARCHAR(30)) + '/' AS hierarchyid),
t.parent_id as trigger_parent_id
FROM dependencies d
JOIN sys.triggers t
ON d.[object_id] = t.parent_id
WHERE d.is_updated = 1
AND tree.GetLevel() < 10
AND CAST(d.tree.ToString() as varchar(1000)) not like '%' + cast(t.[object_id] % 10000 as varchar(1000)) + '%'
)
SELECT replicate('—', tree.GetLevel() - 1) + ' ' + [object_name],
[type_desc] as [type],
tree.ToString() as dependencies
FROM dependencies
ORDER BY tree
I don’t like using git for source control. It’s the worst source control system (except for all the others). My biggest beef is that many of the commands are unintuitive.
Look how tricky some of these common use cases can be: Top Voted Stackoverflow Questions tagged Git. The top 3 questions have over ten thousand votes! This shows a mismatch between how people want to use git and how git is designed to be used.
I want to show the set of commands that I use most. These commands cover 95% of my use of git.
Initial Setup
One-time tasks include downloading git and signing up for github or bitbucket. My team uses github, but yours might use gitlab, bitbucket or something else.
Here’s my typical workflow. Say I want to work on some files in a project on a remote server:
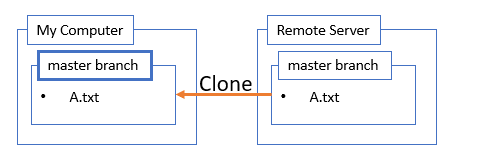
Clone a Repository
My first step is to find the repository for the project. Assuming I’m not starting a project from scratch, I find and copy the location of the repository from a site like github or bitbucket. So the clone command looks like this:
This downloads all the files so I have my own copy to work with.
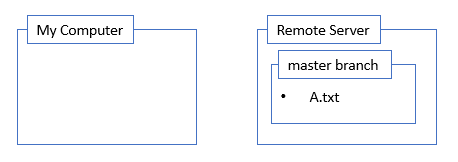
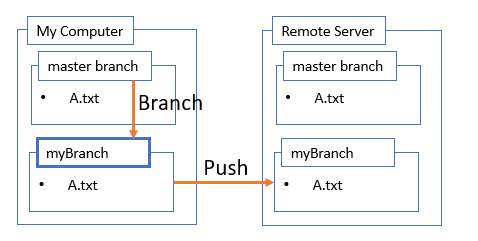
Create a Branch
Next I create a branch. Branches are “alternate timelines” for a repository. The real timeline or branch is called master. One branch can be checked out at a time, so after I create a branch, I check out that branch. In the diagram, I’ve indicated the checkout branch in bold. I like to immediately push that branch back to the remote server. I can always refer to the remote server as “origin”. All this is done with these commands:
Now it’s time to make changes. This has nothing to do with git but it’s part of my workflow. In my example here I’m adding a file B.txt.
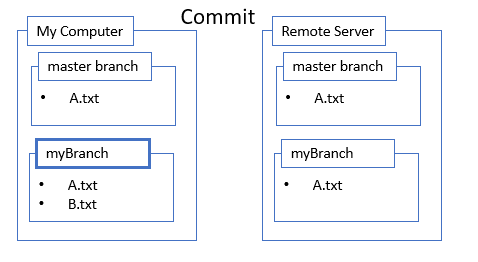
Stage Changes
These changes aren’t part of the branch yet though! If I want them to be part of the branch. I have to commit my changes. That’s done in two parts. The first part is to specify the changes I want to commit. That’s called staging and it’s done with git add. I almost always want to commit everything, so the command becomes:
git add *
git add *
Commit Changes
The second part is to actually commit the files to the branch with a commit message:
git commit -m "my commit message"
git commit -m "my commit message"
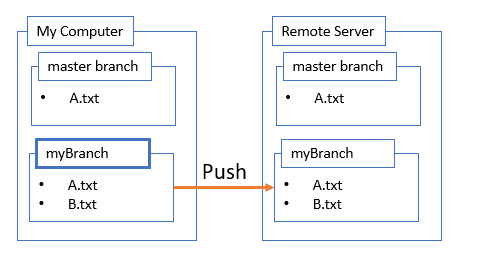
Push Changes
I’m happy with the changes I made to my branch so I want to share them with the rest of the world starting with the remote server.
git push origin myBranch
git push origin myBranch
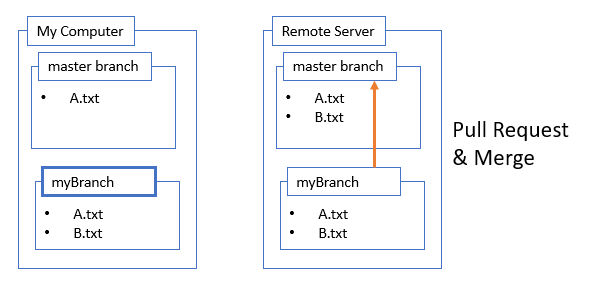
Create a Pull Request and Merge to master
In fact I’m so happy with these changes, I want to include them in master, the real timeline. But not so fast! This is where collaboration and teamwork become important. I create a pull request and then if I get the approval of my teammates, I can merge.
It sounds like a chore, but luckily I don’t have to memorize any git commands for this step because of sites like github or bitbucket. They have a really nice web site and UI where teams can discuss changes before approving them. Once the changes are approved and merged, master now has the changes.
Once it’s merged. Just to complete the circle, I can pull the results of the merge back to my own computer with a pull
git pull
git checkout master
git pull
git checkout master
Other Use Cases
Where Am I?
To find out where I am in my workflow, I like to use:
git status
git status
This one command can tell me what branch I’m on. Whether there are changes that can be pushed or pulled. What files have changed and what changes are staged.
Merge Conflicts
With small frequent changes, merge conflicts become rare. But they still happen. Merge conflicts are a pain in the neck and to this day I usually end up googling “resolving git merge conflicts”.
Can’t this Be Easier?
There are so many programs and utilities available whose only purpose is to make this stuff easier. But they don’t. They make some steps easy, and some steps impossible. Whenever I really screw things up, I delete everything and start from scratch at the cloning step. I find I have to do that more often when I use a tool that was supposed to make my life easier.
One Exception
The only exception to this rule is Visual Studio Code. It’s a real treat to use. I love it.
Maybe you like the command line. Maybe you have a favorite “git-helper” application. No matter how you use git, in every case, you still have to understand the workflow you’re using and that’s what I’ve tried to describe here.
Where To Next
If you want to really get good at this stuff. I recently learned of a great online resource (thanks Cressa!) at https://learngitbranching.js.org/. It’s a great interactive site that teaches more about branching. You will very quickly learn more than the bare minimum required. I recommend it.