


So check out this code, what’s going on here?
begin transaction insert d1.dbo.T1 values (1); insert d2.dbo.T1 values (1); commit |
The transaction is touching two different databases. So it makes sense that the two actions should be atomic and durable together using the one single transaction.
However, databases implement durability and atomicity using their own transaction log. Each transaction log takes care of its own database. So from another point of view, it makes sense that these are two separate transactions.
Which is it? Two transaction or one transaction?

It’s One Transaction (Mostly)
Microsoft’s docs are pretty clear (Thanks Mladen Prajdic for pointing me to it). Distributed Transactions (Database Engine) says:
A transaction within a single instance of the Database Engine that spans two or more databases is actually a distributed transaction. The instance manages the distributed transaction internally; to the user, it operates as a local transaction.
I can actually see that happening with this demo script:
use master if exists (select * from sys.databases where name = 'D1') begin alter database D1 set single_user with rollback immediate; drop database D1; end go if exists (select * from sys.databases where name = 'D2') begin alter database D2 set single_user with rollback immediate; drop database D2; end go create database d1; go create database d2; go create table d1.dbo.T1 (id int); create table d2.dbo.T1 (id int); go use d1; CHECKPOINT; go begin transaction insert d1.dbo.T1 values (1); insert d2.dbo.T1 values (1); commit select [Transaction ID], [Transaction Name], Operation, Context, [Description] from fn_dblog(null, null); |
That shows a piece of what’s going on in the transaction log like this:
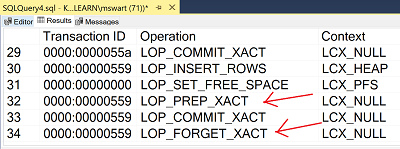
If you’re familiar with fn_dblog output (or even if you’re not), notice that when a transaction touches two databases, there are extra entries in the transaction log. D1 has LOP_PREP_XACT and LOP_FORGET_XACT and D2 only has LOP_PREP_XACT. Grahaeme Ross wrote a lot more about what this means in his article Understanding Cross-Database Transactions in SQL Server
Well that’s good. I can count on that can’t I?
Except When …
You Break Atomicity On Purpose
Well, they are two databases after all. If you want to restore one database to a point in time before the transaction occurred but not the other, I’m not going to stop you.
Availability Groups
But there’s another wrench to throw in with Availability Groups. Again Microsoft’s docs are pretty clear on this (Thanks Brent for pointing me to them). In Transactions – availability groups and database mirroring they point out this kind of thing is pretty new:
In SQL Server 2016 SP1 and before, cross-database transactions within the same SQL Server instance are not supported for availability groups.
There’s support in newer versions, but the availability group had to have been created with WITH DTC_SUPPORT = PER_DB. There’s no altering the availability group after it’s been created.
It’s also interesting that availability groups’ older brother, database mirroring is absolutely not supported. Microsoft says so several times and wants you to know that if you try and you mess up, it’s on you:
… any issues arising from the improper use of distributed transactions are not supported.
Long story short:
- Cross DB Transactions in the same server are supported with Availability Groups in SQL Server 2017 and later
- Cross DB Transactions are not supported with mirrored databases at all

The mirroring part is so diabolically tricky because cross-database transactions work just fine – it’s that under extreme conditions, some of the data just isn’t there on failover, and there’s no indication that data was lost. Good times.
That was a fun engagement to track down because when you’re troubleshooting it later, people don’t connect the dots between missing data and a mirroring failover. They just say, “Some rows are missing in some of our tables, and we don’t understand how that could be possible.” Automatic database mirroring failover happens for individual databases, so you can have one database fail over without bringing over the related partners. If you’ve got a DBA who’s scripted failovers so that if one database fails over, the rest follow within a few seconds, then it’s possible that failovers are happening and users aren’t even really aware that it’s happening. If said DBA isn’t diligent about logging when failovers happen, or telling the end users, then the troubleshooting on the missing rows is an absolute nightmare.
Comment by Brent Ozar — May 15, 2020 @ 11:13 am
Wow! That’s good to know.
There is definitely a huge difference between things that aren’t allowed (giving error messages), and things which are unsupported. The behavior can almost be worse. Like It can seem fine most of the time but then bite you hard in mysterious ways when you least expect it.
Comment by Michael J. Swart — May 15, 2020 @ 11:16 am
[…] Michael J. Swart explains how cross-database transactions work on a single instance: […]
Pingback by Handling Cross-Database Transactions – Curated SQL — May 18, 2020 @ 8:10 am
What Brent calls out here in regards to Mirroring and MSDTC just scratches the surface too. The reason this appears to work is due to the local MSDTC which is on and running away happily by default. It makes everything look like it’s working until you have a failover and get a suspect database. This is a HUGE pitfall in my eyes that I have seen bite many customers and it’s just sitting out there silently waiting to bite many more. If you want MSDTC to be HA (and why wouldn’t you if you have an FCI or AG since that’s the whole point) the bottom line is you need the log to be on shared storage. Here are a couple more articles you might find interesting.
https://www.ryanjadams.com/2019/10/msdtc-best-practices-with-an-availability-group/
https://www.ryanjadams.com/2018/07/msdtc-configuration-sql-support/
Comment by Ryan Adams — May 18, 2020 @ 11:03 am
@ryanjadams
Thanks for the comment. It raised a few questions.
I know that cross-instance transactions (linked servers) need msdtc, but do cross-database transactions?
If I never use “BEGIN DISTRIBUTED TRANSACTION” or linked servers, then does SQL Server need MSDTC, I was able to run the cross-database transaction in this post on my stand-alone laptop with the MSDTC service disabled. In Grahaeme Ross’s article, he points out that Cross Database Transactions don’t use the MS DTC (according to a conversation he had with an engineer at Microsoft) see https://www.red-gate.com/simple-talk/sql/database-administration/understanding-cross-database-transactions-in-sql-server/
I have to be honest, I was thinking of looking at this cross database transaction in order to help avoid a transaction log bottleneck.
Having transaction logs for the different databases on separate volumes means that together they can support more throughput than one volume could.
Comment by Michael J. Swart — May 19, 2020 @ 11:16 am
I believe there are some scenarios in which a cross database transaction will get promoted to the MSDTC, but I would have to go dig through the code to find those. It’s not common though. In fact this is how we handle it in Azure SQL MI. You’ll notice that MI does not support the MSDTC, but it does handle cross database (not cross instance) transactions because we handle that in the code. You’ll also note that it supports linked servers (there are some limitations) which seems odd if it doesn’t support MSDTC, but if you dig into linked servers you’ll see it is not that odd after all. There is a setting in linked servers that allows transactions to use the MSDTC and you can uncheck that so they do not get promoted.
I hope that helps. I will say for your last sentence that putting the logs of the DBs on different drives is going to help for other reasons (with some exceptions), but if you have high MSDTC it can beneficial to have its log on different/fast storage.
Comment by Ryan Adams — May 19, 2020 @ 7:06 pm
“There’s support in newer versions, but the availability group had to have been created with WITH DTC_SUPPORT = PER_DB. There’s no altering the availability group after it’s been created.”
Looks like it can be adjusted on 2017 (at least running CU21 it can):
USE [master]
GO
ALTER AVAILABILITY GROUP [xxx]
SET (DTC_SUPPORT = PER_DB);
GO
Comment by Arnold Lieberman — August 24, 2020 @ 11:20 am