Good ways and bad ways to update or insert rows
- The Setup
- AntiPatterns
- Vanilla Solution
- MERGE Statement
- Inside a Transaction
- Inside a Serializable Transaction
- Using IGNORE_DUP_KEY
- Patterns
- Inside a Transaction With Lock Hints (Update More Common)
- Inside a Transaction With Lock Hints (Insert More Common)
- MERGE Statement With Serializable
- Just Do It
- Performance and Other Concerns
In 2015, Postgres added support for ON CONFLICT DO UPDATE to their INSERT statements. Their docs say that using this syntax guarantees an atomic INSERT or UPDATE outcome; one of those two outcomes is guaranteed, even under high concurrency.
Now, that is one amazing feature isn’t it? Postgres worked really hard to include that feature and kudos to them. I would trade ten features like stretch db for one feature like this. It makes a very common use case simple. And it takes away the awkwardness from the developer.
But if you work with SQL Server, the awkwardness remains and you have to take care of doing UPSERT correctly under high concurrency.
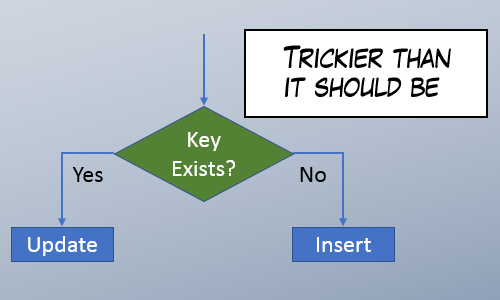
I wrote a post in 2011 called Mythbusting: Concurrent Update/Insert Solutions. But since then, I learned new things, and people have suggested new UPSERT methods. I wanted to bring all those ideas together on one page. Something definitive that I can link to in the future.
The Setup
I’m going consider multiple definitions of a procedure called s_AccountDetails_Upsert. The procedure will attempt to perform an UPDATE or INSERT to this table:
CREATE TABLE dbo.AccountDetails ( Email NVARCHAR(400) NOT NULL CONSTRAINT PK_AccountDetails PRIMARY KEY, Created DATETIME NOT NULL DEFAULT GETUTCDATE(), Etc NVARCHAR(MAX) ); |
Then I’m going to test each definition by using a tool like SQL Query Stress to run this code
declare @rand float = rand() + DATEPART( second, getdate() ); declare @Email nvarchar(330) = cast( cast( @rand * 100 as int) as nvarchar(100) ) + '@somewhere.com'; declare @Etc nvarchar(max) = cast( newid() as nvarchar(max) ); exec dbo.s_AccountDetails_Upsert @Email, @Etc; |
Antipattern: Vanilla Solution
If you don’t care about concurrency, this is a simple implementation. Nothing fancy here:
CREATE PROCEDURE s_AccountDetails_Upsert ( @Email nvarchar(4000), @Etc nvarchar(max) ) AS IF EXISTS ( SELECT * FROM dbo.AccountDetails WHERE Email = @Email ) UPDATE dbo.AccountDetails SET Etc = @Etc WHERE Email = @Email; ELSE INSERT dbo.AccountDetails ( Email, Etc ) VALUES ( @Email, @Etc ); |
Unfortunately, under high concurrency, this procedure fails with primary key violations.
Antipattern: MERGE Statement
The MERGE statement still suffers from the same concurrency issues as the vanilla solution.
CREATE PROCEDURE s_AccountDetails_Upsert ( @Email nvarchar(4000), @Etc nvarchar(max) ) AS MERGE dbo.AccountDetails AS myTarget USING (SELECT @Email Email, @Etc etc) AS mySource ON mySource.Email = myTarget.Email WHEN MATCHED THEN UPDATE SET etc = mySource.etc WHEN NOT MATCHED THEN INSERT (Email, Etc) VALUES (@Email, @Etc); |
Primary Key violations are still generated under high concurrency. Even though it’s a single statement, it’s not isolated enough.
Antipattern: Inside a Transaction
If you try putting the vanilla solution inside a transaction, it makes the whole thing atomic, but still not isolated. You still get primary key violations:
CREATE PROCEDURE s_AccountDetails_Upsert ( @Email nvarchar(4000), @Etc nvarchar(max) ) AS BEGIN TRAN IF EXISTS ( SELECT * FROM dbo.AccountDetails WHERE Email = @Email ) UPDATE dbo.AccountDetails SET Etc = @Etc WHERE Email = @Email; ELSE INSERT dbo.AccountDetails ( Email, Etc ) VALUES ( @Email, @Etc ); COMMIT |
Antipattern: Inside a Serializable Transaction
So this should be isolated enough, but now it’s vulnerable to deadlocks:
CREATE PROCEDURE s_AccountDetails_Upsert ( @Email nvarchar(4000), @Etc nvarchar(max) ) AS SET TRANSACTION ISOLATION LEVEL SERIALIZABLE BEGIN TRAN IF EXISTS ( SELECT * FROM dbo.AccountDetails WHERE Email = @Email ) UPDATE dbo.AccountDetails SET Etc = @Etc WHERE Email = @Email; ELSE INSERT dbo.AccountDetails ( Email, Etc ) VALUES ( @Email, @Etc ); COMMIT |
Antipattern: Using IGNORE_DUP_KEY
I want to mention one more bad solution before I move on to the good solutions. It works and it’s interesting, but it’s a bad idea.
ALTER TABLE dbo.AccountDetails DROP CONSTRAINT PK_AccountDetails; ALTER TABLE dbo.AccountDetails ADD CONSTRAINT PK_AccountDetails PRIMARY KEY ( Email ) WITH ( IGNORE_DUP_KEY = ON ) GO CREATE PROCEDURE dbo.s_AccountDetails_Upsert ( @Email nvarchar(4000), @Etc nvarchar(max) ) AS -- This statement will not insert if there's already a duplicate row, -- But it won't raise an error either INSERT dbo.AccountDetails ( Email, Etc ) VALUES ( @Email, @Etc ); UPDATE dbo.AccountDetails SET @Etc = Etc WHERE @Email = Email; |
So what are some better solutions?
Pattern: Inside a Transaction With Lock Hints (Update More Common)
My prefered solution.
CREATE PROCEDURE s_AccountDetails_Upsert ( @Email nvarchar(4000), @Etc nvarchar(max) ) AS SET XACT_ABORT ON; BEGIN TRAN UPDATE TOP (1) dbo.AccountDetails WITH (UPDLOCK, SERIALIZABLE) SET Etc = @Etc WHERE Email = @Email; IF (@@ROWCOUNT = 0) BEGIN INSERT dbo.AccountDetails ( Email, Etc ) VALUES ( @Email, @Etc ); END COMMIT |
Using some tips from Aaron Bertrand in Please stop using this UPSERT anti-pattern.
This is a solid solution, but every implementation is different so every time you use this pattern, test for concurrency.
Pattern: Inside a Transaction With Lock Hints (Insert More Common)
CREATE PROCEDURE s_AccountDetails_Upsert ( @Email nvarchar(4000), @Etc nvarchar(max) ) AS SET XACT_ABORT ON; BEGIN TRAN INSERT dbo.AccountDetails ( Email, Etc ) SELECT @Email, @Etc WHERE NOT EXISTS ( SELECT * FROM dbo.AccountDetails WITH (UPDLOCK, SERIALIZABLE) WHERE Email = @Email ) IF (@@ROWCOUNT = 0) BEGIN UPDATE TOP (1) dbo.AccountDetails SET Etc = @Etc WHERE Email = @Email; END COMMIT |
Pattern: MERGE Statement With Serializable Isolation
Nice, but be careful with MERGE statements.
CREATE PROCEDURE s_AccountDetails_Upsert ( @Email nvarchar(4000), @Etc nvarchar(max) ) AS SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; MERGE dbo.AccountDetails AS myTarget USING (SELECT @Email Email, @Etc etc) AS mySource ON mySource.Email = myTarget.Email WHEN MATCHED THEN UPDATE SET etc = mySource.etc WHEN NOT MATCHED THEN INSERT (Email, Etc) VALUES (@Email, @Etc); |
For alternative syntax, skip the SET TRANSACTION ISOLATION LEVEL SERIALIZABLE and include a lock hint: MERGE dbo.AccountDetails WITH (HOLDLOCK) AS myTarget.
Pattern: Just Do It
Just try it and catch and swallow any exception
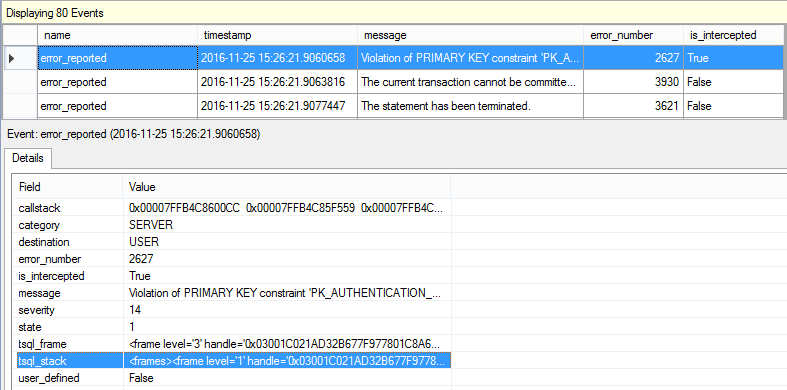
CREATE PROCEDURE s_AccountDetails_Upsert ( @Email nvarchar(4000), @Etc nvarchar(max) ) AS BEGIN TRY INSERT INTO dbo.AccountDetails (Email, Etc) VALUES (@Email, @Etc); END TRY BEGIN CATCH -- ignore duplicate key errors, throw the rest. IF ERROR_NUMBER() IN (2601, 2627) UPDATE dbo.AccountDetails SET Etc = @Etc WHERE Email = @Email; END CATCH |
I wrote a post about it in Ugly Pragmatism For The Win.
And I wrote about a rare problem with it in Case study: Troubleshooting Doomed Transactions.
I have no concurrency concerns here but because of this issue – not to mention performance concerns – it’s no longer my first preference.
Performance and Other Concerns
When describing each pattern so far, I haven’t paid attention to performance, just concurrency. There are many opportunities to improve the performance of these solutions. In particular, pay very close attention to your average use case. If your workload UPDATEs a row 99% of the time and INSERTs a row only 1% of the time, then optimal implementation will look different than if the UPDATE and INSERT frequency is reversed.
Check out these links (thanks Aaron Bertrand)