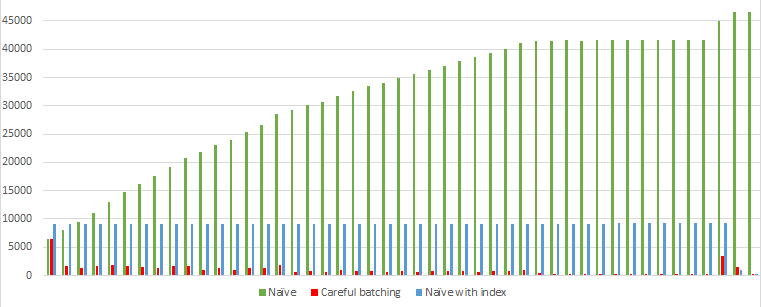
Takeaway: I look at different features to see whether non-updates are treated the same as other updates. Most of the time they are.

According to Microsoft’s documentation, an UPDATE statement “changes existing data in a table or view”. But what if the values don’t actually change? What if affected rows are “updated” with the original values? Some call these updates non-updating. This leads to a philosophical question: “If an UPDATE statement doesn’t change any column to a different value, has the row been updated?”
I answer yes to that question. I consider all affected rows as “updated” regardless of whether the values are different. I think of the UPDATE statement as more of an OVERWRITE statement. I also think of “affected rows” rather than “changed rows”. In most cases SQL Server thinks along the same lines.
I list some features and areas of SQL Server and whether non-updating updates are treated the same or differently than other updates:
The Performance of Non-Updates Non-Updates treated differently than other Updates
In 2010, Paul White wrote The Impact of Non-Updating Updates where he points out optimizations Microsoft has made to avoid unnecessary logging when performing some non-updating updates. It’s a rare case where SQL Server actually does pay attention to whether values are not changing to avoid doing unnecessary work.
In the years since, I’ve noticed that this optimization hasn’t changed much except that Microsoft has extended these performance improvements to cases where RCSI or SI is enabled.
Regardless of this performance optimization, it’s still wise to limit affected rows as much as possible. In other words, I still prefer
UPDATE FactOnlineSales SET DiscountAmount = NULL WHERE CustomerKey = 19036 AND DiscountAmount IS NOT NULL; |
over this logically equivalent version:
UPDATE FactOnlineSales SET DiscountAmount = NULL WHERE CustomerKey = 19036; |
Although the presence of triggers and cascading foreign keys require extra care as we’ll see.
Triggers Non-Updates are treated the same as Updates
Speaking of triggers, remember that inside a trigger, non-updating rows are treated exactly the same as any other changing row. Just remember that:
- Triggers are always invoked, even when there are zero rows affected or even when the table is empty.
- For UPDATE statements, the UPDATE() function only cares about whether a column appeared in the SET clause. It can be useful for short-circuit logic.
- The virtual tables
insertedanddeletedare filled with all affected rows (not just changed rows).
ON UPDATE CASCADE Non-Updates are treated the same as Updates
When foreign keys have ON UPDATE CASCADE set, Microsoft says “corresponding rows are updated in the referencing table when that row is updated in the parent table”.
Non-updating updates are no exception. To demonstrate, I create an untrusted foreign key and perform a non-updating update. It’s not a “no-op”, the constraint is checked as expected.
CREATE TABLE dbo.TestReferenced ( Id INT PRIMARY KEY ); INSERT dbo.TestReferenced (Id) VALUES (1), (2), (3), (4); CREATE TABLE dbo.TestReferrer ( Id INT NOT NULL ); INSERT dbo.TestReferrer (Id) VALUES (2), (4), (6), (8); ALTER TABLE dbo.TestReferrer WITH NOCHECK ADD FOREIGN KEY (Id) REFERENCES dbo.TestReferenced(Id) ON UPDATE CASCADE; -- trouble with this non-updating update: UPDATE dbo.TestReferrer SET Id = Id WHERE Id = 8; -- The UPDATE statement conflicted with the FOREIGN KEY constraint ... |
@@ROWCOUNT Non-Updates are treated the same as Updates
SELECT @@ROWCOUNT returns the number of affected rows in the previous statement, not the number of changed rows.
Temporal Tables Non-Updates are treated the same as Updates
Non-updating updates still generate new rows in the history table. This can lead to puzzling results if you’re not prepared for them. For example, I can make some changes and query the history like this:
INSERT MyTest(Value) VALUES ('Mike') UPDATE MyTest SET Value = 'Michael'; UPDATE MyTest SET Value = 'Michael'; |
When I take the union of rows in the table and the history table, I might see this output:
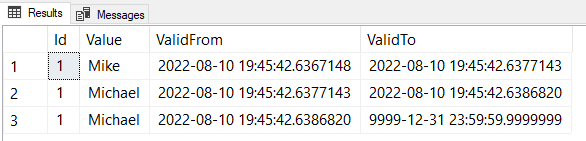
It reminds me of when my GPS says something like “In two miles, continue straight on Highway 81.” The value didn’t change, but there are still two distinct ranges.
Change Tracking Non-Updates are treated the same as Updates
Change tracking could be called “Overwrite Tracking” because all non-updating updates are tracked:
ALTER DATABASE CURRENT set change_tracking = ON (change_retention = 2 days, auto_cleanup = on); GO create table dbo.test (id int primary key); insert dbo.test (id) values (1), (2), (3); alter table dbo.test enable change_tracking with (track_columns_updated = on) -- This statement produces 0 rows: SELECT t.id, c.* FROM CHANGETABLE (CHANGES dbo.Test, 0) AS c JOIN dbo.Test AS t ON t.id = c.id ; -- "update" update dbo.test set id = id; -- This statement produces 3 rows: SELECT t.id, c.* FROM CHANGETABLE (CHANGES dbo.Test, 0) AS c JOIN dbo.Test AS t ON t.id = c.id; |
Change Data Capture (CDC) Non-Updates treated differently than other Updates
Here’s a rare exception where a SQL Server feature is named properly. CDC does indeed capture data changes only when data is changing.
Paul White provided a handy set up for testing this kind of stuff. I reran his tests with CDC turned on. I found that:
- When CDC is enabled, an update statement is always logged and the data buffers are always marked dirty.
- But non-updating updates almost never show up as captured data changes, not even when the update was on a column in the clustering key.
- I was able to generate some CDC changes for non-updates by updating the whole table with an idempotent expression (e.g.
SET some_column = some column * 1)CREATE TABLE dbo.SomeTable ( some_column integer NOT NULL, some_data integer NOT NULL, index ix_sometable unique clustered (some_column) ); UPDATE dbo.SomeTable SET some_column = some_column*1;
If you’re using this feature, this kind of stuff is important to understand! If you’re using CDC for DIY replication (God help you), then maybe the missing non-updates are acceptable. But if you’re looking for a kind of audit, or a way to analyze user-interactions with the database, then CDC doesn’t give the whole picture and is not the tool for you.