Another recap of a problem we recently tackled where we had to find out why a doomed transaction was still trying to do work. A doomed transaction is one that is about to roll back. In our case, it was caused by a rare set of circumstances:
If you don’t feel like reading ahead, here are the lessons. Don’t program in T-SQL. Avoid triggers. Extended events are awesome.
Getting Error 3930
Our app was getting an error coming from SQL Server. Error 3930 gives this message:
Msg 3930, Level 16, State 1, Line 14
The current transaction cannot be committed and cannot support operations that
write to the log file. Roll back the transaction.
Google pointed me to this Stackoverflow question where Remus Rusanu talks about doomed transactions. You’re not allowed to do work in a catch block if your transaction is doomed. He then points to more information about uncommittable transactions in the TRY/CATCH docs. According to the TRY/CATCH docs, you can get this kind of error when XACT_ABORT is turned ON. This is something we do and I wrote about why in Don’t Abandon Your Transactions.
So there’s a CATCH block catching some error in a TRY block. Now I wonder what that error is. The SqlException that got raised to the client only had the 3930 error above. It had nothing about the original error. I did have the procedure name though. I can look there.
Complicated Procedure
So I took a look at the procedure getting called. I saw that it was calling another procedure. And that procedure called other procedures. It was a big complicated mess. The calling tree looked like this:
Something Complicated
So the procedure was complicated and it used explicit transactions, but I couldn’t find any TRY/CATCH blocks anywhere! What I needed was a stack trace, but for T-SQL. People don’t talk about T-SQL stack traces very often. Probably because they don’t program like this in T-SQL. We can’t get a T-SQL stack trace from the SQLException (the error given to the client), so we have to get it from the server.
More Info Needed From the Server
So luckily, extended events do have T-SQL stack traces. I wanted to look at those stack traces whenever there was an error on the server. My session looked something like this:
CREATE EVENT SESSION[errors]ON SERVER
ADD EVENT sqlserver.error_reported(ACTION(sqlserver.sql_text,sqlserver.tsql_stack))ADD TARGET package0.event_file(SET filename=N'errors')
GO
CREATE EVENT SESSION [errors] ON SERVER
ADD EVENT sqlserver.error_reported(
ACTION(sqlserver.sql_text,sqlserver.tsql_stack))
ADD TARGET package0.event_file(SET filename=N'errors')
GO
Then I waited
Eventually It Failed Again
Woohoo!
First I looked for the error. The one where error_code = 3930. I did it using Management Studio to view the session’s data.
Then I looked at the error immediately before it. The one where is_intercepted = true. That looks something like this
The T-SQL stack trace for that error is formatted as xml
select * from sys.dm_exec_sql_text(0x03001C021AD32B677F977801C8A6000001000000000000000000000000000000000000000000000000000000)
The Original Error
Here’s what I found. The original error was a PK violation in a procedure using the Just Do It (JDI) pattern. It’s a technique which tackles upsert concurrency problems by inserting a row and catching and suppressing any PK errors that might be thrown.
So that’s where the TRY/CATCH block was.
Also, the stack trace told me that the procedure was called from a trigger. So my complicated procedure was actually more complicated than I thought. It actually looked like this
Something More Complicated
That’s why i didn’t see it before. I hate the way triggers can hide complexity. They’re sneaky.
The CATCH block catches a real error and the XACT_ABORT setting dooms the transaction. Because I didn’t do anything with the error, the transaction was allowed to continue. It was actually some query in s_ProcM that attempted to do work inside the doomed transaction.
To fix, we adjusted the text of the query to be concurrent without using TRY/CATCH for flow control. For the extra curious, we used method 4 from Mythbusting: Concurrent Update/Insert Solutions.
Lessons
Don’t use the Just Do It (JDI) upsert pattern inside triggers
In fact don’t use TRY/CATCH for flow control
And also don’t use triggers
In fact don’t program inside SQL Server if you can help it
Oh, and Extended Events include a T-SQL stack trace if God forbid you need it
Merry Christmas readers! It’s story time. This is about a problem I encountered a few weeks ago. We were looking at a production site using sp_whoisactive and we noticed a lot of blocking on one particular procedure. I’m going to explain how we tackled it.
In this case, I think it’s interesting that we were able to mitigate the problem without requiring sysadmin access.
The Symptoms
Using sp_whoisactive and other tools, we noticed several symptoms.
SQLException timeout errors were reported by the app when calling one procedure in particular.
Many sessions were executing that procedure concurrently. Or at least they were attempting to.
There was excessive blocking and the lead blocker was running the same procedure.
The lead blocker had been running the longest (about 29 seconds)
The blocking was caused by processes waiting on Sch-M locks for a table used by that query
Here’s what was going on:
SQL Server was struggling to compile the procedure in time and the application wouldn’t let it catch its breath. The query optimizer was attempting to create statistics automatically that it needed for optimizing the query, but after thirty seconds, the application got impatient and cancelled the query.
So the compilation of the procedure was cancelled and this caused two things to happen. First, the creation of the statistics was cancelled. Second, the next session in line was allowed to run. But the problem was that the next session had already spent 28 seconds blocked by the first session and only had two seconds to try to compile a query before getting cancelled itself.
The frequent calls to the procedure meant that nobody had time to compile this query. And we were stuck in an endless cycle of sessions that wanted to compile a procedure, but could never get enough time to do it.
Why was SQL Server taking so long to compile anyway?
After a bunch of digging, we found out that a SQL Server bug was biting us. This bug involved
SQL Server 2014
Trace flag 2389 and 2390
Filtered Indexes on very large base tables
Kind of a perfect storm of factors that exposed a SQL Server quirk that caused long compilation times, timeouts and pain.
What We Did About It
Well, in this case, I think that the traceflag 2389, 2390 kind of outlived its usefulness (the cure is worse than the disease and all that). So the main fix for this problem is to get rid of those traceflags. But it would be some time before we could get that rolled out.
So for the short term, we worked at getting that procedure compiled and into SQL Server’s cache.
We called the procedure ourselves in Management Studio. Our call waited about thirty seconds before it got its turn to run. Then it spent a little while to compile and run the procedure. Presto! The plan is in the cache now! And everything’s all better right? Nope. Not quite. The timeouts continued.
If you’ve read Erland Sommarskog’s Slow in the Application, Fast in SSMS you may have guessed what’s going on. When we executed the procedure in SSMS, it was using different settings. So the query plan we compiled couldn’t be reused by the application. Remember, all settings (including ARITHABORT) need to match before cached plans can be reused by different sessions. We turned ARITHABORT off in SSMS and called the procedure again.
After a minute, the query completed and all blocking immediately stopped. Whew! The patient was stable.
The whole experience was a pain. And an outage is an outage. Though the count of the snags for the year had increased …
Adam Machanic tweeted this advice last week:
https://twitter.com/AdamMachanic/status/799365663781519360
Are you missing any of these check constraints? Run this query to check.
This query looks for any columns in the same table that begin with “Start” and “End”. It then looks for check constraints that reference both these columns. If it doesn’t find them, it suggests a check constraint.
WITH StartColumnNames AS(SELECTobject_id,
column_id,
name AS column_name
FROM sys.columnsWHERE name like'start%'),
EndColumnNames AS(SELECTobject_id,
column_id,
name AS column_name
FROM sys.columnsWHERE name like'end%')SELECT t.object_id,
OBJECT_SCHEMA_NAME(t.object_id)AS[schema_name],
t.[name]AS table_name,
s.column_nameAS start_column,
e.column_nameAS end_column,
N'ALTER TABLE '+QUOTENAME(OBJECT_SCHEMA_NAME(t.object_id))+ N'.'+QUOTENAME(t.name)+
N' ADD CONSTRAINT '+QUOTENAME(N'CK_'+ t.name+ N'_'+ s.column_name+ N'_'+ e.column_name)+
N' CHECK ('+QUOTENAME(s.column_name)+ N' <= '+QUOTENAME(e.column_name)+ N');'as check_suggestion
FROM StartColumnNames s
JOIN EndColumnNames e
ON s.object_id= e.object_idAND s.column_id<> e.column_idANDREPLACE(s.column_name, 'start', 'end')= e.column_nameJOIN sys.tables t
ON t.object_id= s.object_idWHERENOTEXISTS(SELECT*FROM sys.check_constraints c
JOIN sys.sql_expression_dependencies start_dependency
ON start_dependency.referencing_id= c.object_idAND start_dependency.referenced_id= t.object_idAND start_dependency.referenced_minor_id= s.column_idJOIN sys.sql_expression_dependencies end_dependency
ON end_dependency.referencing_id= c.object_idAND end_dependency.referenced_id= t.object_idAND end_dependency.referenced_minor_id= e.column_idWHERE c.parent_object_id= t.object_id)
WITH StartColumnNames AS
(
SELECT object_id,
column_id,
name AS column_name
FROM sys.columns
WHERE name like 'start%'
),
EndColumnNames AS
(
SELECT object_id,
column_id,
name AS column_name
FROM sys.columns
WHERE name like 'end%'
)
SELECT t.object_id,
OBJECT_SCHEMA_NAME(t.object_id) AS [schema_name],
t.[name] AS table_name,
s.column_name AS start_column,
e.column_name AS end_column,
N'ALTER TABLE ' + QUOTENAME(OBJECT_SCHEMA_NAME(t.object_id)) + N'.' + QUOTENAME(t.name) +
N' ADD CONSTRAINT ' +
QUOTENAME(N'CK_' + t.name + N'_' + s.column_name + N'_' + e.column_name) +
N' CHECK (' + QUOTENAME(s.column_name) + N' <= ' + QUOTENAME(e.column_name) + N');' as check_suggestion
FROM StartColumnNames s
JOIN EndColumnNames e
ON s.object_id = e.object_id
AND s.column_id <> e.column_id
AND REPLACE(s.column_name, 'start', 'end') = e.column_name
JOIN sys.tables t
ON t.object_id = s.object_id
WHERE NOT EXISTS
(
SELECT *
FROM sys.check_constraints c
JOIN sys.sql_expression_dependencies start_dependency
ON start_dependency.referencing_id = c.object_id
AND start_dependency.referenced_id = t.object_id
AND start_dependency.referenced_minor_id = s.column_id
JOIN sys.sql_expression_dependencies end_dependency
ON end_dependency.referencing_id = c.object_id
AND end_dependency.referenced_id = t.object_id
AND end_dependency.referenced_minor_id = e.column_id
WHERE c.parent_object_id = t.object_id
)
Caveats
Don’t blindly run scripts that you got from some random guy’s blog. Even if that someone is me. That’s terribly irresponsible.
But this query may be useful if you do want to look for a very specific, simple kind of constraint that may match your business specs. These constraints are just suggestions and may not match your business rules. For example, when I run this query on Adventureworks, I get one “missing” check constraint for HumanResources.Shift(StartTime, EndTime) and when I look at the contents of the Shift table, I get this data:
Notice that I can’t create a constraint on this table because of the night shift. The constraint doesn’t make sense here.
Creating constraints on existing tables may take time if the table is huge. Locks may be held on that table for an uncomfortably long time.
Of course if your table has data that would violate the constraint, you can’t create it. But now you have to make some other choices. You can correct or delete the offending data or you can add the constraint with NOCHECK.
There are so many ways to look inside SQL Server. New extended events and dynamic management views are introduced every version. But if you want to collect something that’s unavailable, with a little bit of creativity, you can create your own tools.
I had a deadlock graph I wanted to tackle, but I was having trouble reproducing it. I needed to know more about the queries involved. But the query plans were no longer in cache. So here’s the problem
Can I collect the execution plans that were used for the queries involved in a deadlock graph?
I want to use that information to reproduce – and ultimately fix – the deadlock.
The Right Tool For the Job
If you don’t have enough data to get to the root cause of an issue, put something in place for next time.
Can I Use Out-Of-The-Box Extended Events?
I’m getting used to extended events and so my first thought was “Is there a query plan field I can collect with the deadlock extended event? There is not. Which isn’t too surprising. Deadlock detection is independent of any single query.
So How Do I Get To The Execution Plans?
So when I look at a deadlock graph, I can see there are sql_handles. Given that, I can grab the plan_handle and then the query plan from the cache, but I’m going to need to collect it automatically at the time the deadlock is generated. So I’m going to need
XML shredding skills
Ability to navigate DMVs to get at the cached query plans
A way to programatically respond to deadlock graph events (like an XE handler or a trigger)
Responding Automatically to Extended Events
This is when I turned to #sqlhelp. And sure enough, six minutes later, Dave Mason helped me out:
I had never heard of Event Notifications, so after some googling, I discovered two things. The first thing is that I can only use Event Notifications with DDL or SQLTrace events rather than the larger set of extended events. Luckily deadlock graphs are available in both. The second thing is that Event Notifications aren’t quite notifications the way alerts are. They’re a way to push event info into a Service Broker queue. If I want automatic actions taken on Service Broker messages, I have to define and configure an activation procedure to process each message. In pictures, here’s my plan so far:
Will It Work?
I think so, I’ve had a lot of success creating my own tools in the past such as
USE master;
IF(DB_ID('DeadlockLogging')ISNOTNULL)BEGINALTERDATABASE DeadlockLogging SET SINGLE_USER WITHROLLBACKIMMEDIATE;
DROPDATABASE DeadlockLogging;
ENDCREATEDATABASE DeadlockLogging WITH TRUSTWORTHY ON;
GO
USE master;
IF (DB_ID('DeadlockLogging') IS NOT NULL)
BEGIN
ALTER DATABASE DeadlockLogging SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE DeadlockLogging;
END
CREATE DATABASE DeadlockLogging WITH TRUSTWORTHY ON;
GO
Create the Service Broker Objects
I’ve never used Service Broker before, so a lot of this comes from examples found in Books Online.
use DeadlockLogging;
CREATE QUEUE dbo.LogDeadlocksQueue;
CREATE SERVICE LogDeadlocksService
ON QUEUE dbo.LogDeadlocksQueue([http://schemas.microsoft.com/SQL/Notifications/PostEventNotification]);
CREATE ROUTE LogDeadlocksRoute
WITH SERVICE_NAME ='LogDeadlocksService',
ADDRESS ='LOCAL';
-- add server level notificationIFEXISTS(SELECT*FROM sys.server_event_notificationsWHERE[name]='LogDeadlocks')DROP EVENT NOTIFICATION LogDeadlocks ON SERVER;
DECLARE @SQLNVARCHAR(MAX);
SELECT @SQL= N'
CREATE EVENT NOTIFICATION LogDeadlocks
ON SERVER
FOR deadlock_graph -- name of SQLTrace event type
TO SERVICE ''LogDeadlocksService'', '''+CAST(service_broker_guid asnvarchar(max))+''';'FROM sys.databasesWHERE[name]=DB_NAME();
EXECsp_executesql @SQL;
GO
use DeadlockLogging;
CREATE QUEUE dbo.LogDeadlocksQueue;
CREATE SERVICE LogDeadlocksService
ON QUEUE dbo.LogDeadlocksQueue
([http://schemas.microsoft.com/SQL/Notifications/PostEventNotification]);
CREATE ROUTE LogDeadlocksRoute
WITH SERVICE_NAME = 'LogDeadlocksService',
ADDRESS = 'LOCAL';
-- add server level notification
IF EXISTS (SELECT * FROM sys.server_event_notifications WHERE [name] = 'LogDeadlocks')
DROP EVENT NOTIFICATION LogDeadlocks ON SERVER;
DECLARE @SQL NVARCHAR(MAX);
SELECT @SQL = N'
CREATE EVENT NOTIFICATION LogDeadlocks
ON SERVER
FOR deadlock_graph -- name of SQLTrace event type
TO SERVICE ''LogDeadlocksService'', ''' + CAST(service_broker_guid as nvarchar(max))+ ''';'
FROM sys.databases
WHERE [name] = DB_NAME();
EXEC sp_executesql @SQL;
GO
The dynamic SQL is used to fetch the database guid of the newly created database.
a Place to Store Deadlocks
-- Create a place to store the deadlock graphs along with query plan informationCREATESEQUENCE dbo.DeadlockIdentitySTARTWITH1;
CREATETABLE dbo.ExtendedDeadlocks(
DeadlockId bigintnotnull,
DeadlockTime datetimenotnull,
SqlHandle varbinary(64),
StatementStart int,
[Statement]nvarchar(max)null,
Deadlock XML notnull,
FirstQueryPlan XML
);
CREATECLUSTEREDINDEX IX_ExtendedDeadlocks
ON dbo.ExtendedDeadlocks(DeadlockTime, DeadlockId);
GO
-- Create a place to store the deadlock graphs along with query plan information
CREATE SEQUENCE dbo.DeadlockIdentity START WITH 1;
CREATE TABLE dbo.ExtendedDeadlocks
(
DeadlockId bigint not null,
DeadlockTime datetime not null,
SqlHandle varbinary(64),
StatementStart int,
[Statement] nvarchar(max) null,
Deadlock XML not null,
FirstQueryPlan XML
);
CREATE CLUSTERED INDEX IX_ExtendedDeadlocks
ON dbo.ExtendedDeadlocks(DeadlockTime, DeadlockId);
GO
The Procedure That Processes Queue Messages
CREATEPROCEDURE dbo.ProcessDeadlockMessageASDECLARE @RecvMsg NVARCHAR(MAX);
DECLARE @RecvMsgTime DATETIME;
SET XACT_ABORT ON;
BEGINTRANSACTION;
WAITFOR(
RECEIVE TOP(1)
@RecvMsgTime = message_enqueue_time,
@RecvMsg = message_body
FROM dbo.LogDeadlocksQueue), TIMEOUT 5000;
IF(@@ROWCOUNT=0)BEGINROLLBACKTRANSACTION;
RETURN;
ENDDECLARE @DeadlockId BIGINT=NEXTVALUEFOR dbo.DeadlockIdentity;
DECLARE @RecsvMsgXML XML =CAST(@RecvMsg AS XML);
DECLARE @DeadlockGraph XML = @RecsvMsgXML.query('/EVENT_INSTANCE/TextData/deadlock-list/deadlock');
WITH DistinctSqlHandles AS(SELECTDISTINCT node.value('@sqlhandle', 'varchar(max)')as SqlHandle
FROM @RecsvMsgXML.nodes('//frame')AS frames(node))INSERT ExtendedDeadlocks (DeadlockId, DeadlockTime, SqlHandle, StatementStart, [Statement], Deadlock, FirstQueryPlan)SELECT @DeadlockId,
@RecvMsgTime,
qs.sql_handle,
qs.statement_start_offset,
[statement],
@DeadlockGraph,
qp.query_planFROM DistinctSqlHandles s
LEFTJOIN sys.dm_exec_query_stats qs
on qs.sql_handle=CONVERT(VARBINARY(64), SqlHandle, 1)OUTER APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
OUTER APPLY sys.dm_exec_sql_text(CONVERT(VARBINARY(64), SqlHandle, 1)) st
OUTER APPLY (SELECTSUBSTRING(st.[text],(qs.statement_start_offset+2)/2,
(CASEWHEN qs.statement_end_offset=-1THENLEN(CONVERT(NVARCHAR(MAX), st.text))*2ELSE qs.statement_end_offset+2END- qs.statement_start_offset)/2))as sqlStatement([statement]);
-- clean up old deadlocksDECLARE @limitBIGINTSELECTDISTINCTTOP(500) @limit= DeadlockId
FROM ExtendedDeadlocks
ORDERBY DeadlockId DESC;
DELETE ExtendedDeadlocks
WHERE DeadlockId < @limit;
COMMIT
GO
CREATE PROCEDURE dbo.ProcessDeadlockMessage
AS
DECLARE @RecvMsg NVARCHAR(MAX);
DECLARE @RecvMsgTime DATETIME;
SET XACT_ABORT ON;
BEGIN TRANSACTION;
WAITFOR (
RECEIVE TOP(1)
@RecvMsgTime = message_enqueue_time,
@RecvMsg = message_body
FROM dbo.LogDeadlocksQueue
), TIMEOUT 5000;
IF (@@ROWCOUNT = 0)
BEGIN
ROLLBACK TRANSACTION;
RETURN;
END
DECLARE @DeadlockId BIGINT = NEXT VALUE FOR dbo.DeadlockIdentity;
DECLARE @RecsvMsgXML XML = CAST(@RecvMsg AS XML);
DECLARE @DeadlockGraph XML = @RecsvMsgXML.query('/EVENT_INSTANCE/TextData/deadlock-list/deadlock');
WITH DistinctSqlHandles AS
(
SELECT DISTINCT node.value('@sqlhandle', 'varchar(max)') as SqlHandle
FROM @RecsvMsgXML.nodes('//frame') AS frames(node)
)
INSERT ExtendedDeadlocks (DeadlockId, DeadlockTime, SqlHandle, StatementStart, [Statement], Deadlock, FirstQueryPlan)
SELECT @DeadlockId,
@RecvMsgTime,
qs.sql_handle,
qs.statement_start_offset,
[statement],
@DeadlockGraph,
qp.query_plan
FROM DistinctSqlHandles s
LEFT JOIN sys.dm_exec_query_stats qs
on qs.sql_handle = CONVERT(VARBINARY(64), SqlHandle, 1)
OUTER APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
OUTER APPLY sys.dm_exec_sql_text (CONVERT(VARBINARY(64), SqlHandle, 1)) st
OUTER APPLY (
SELECT SUBSTRING(st.[text],(qs.statement_start_offset + 2) / 2,
(CASE
WHEN qs.statement_end_offset = -1 THEN LEN(CONVERT(NVARCHAR(MAX), st.text)) * 2
ELSE qs.statement_end_offset + 2
END - qs.statement_start_offset) / 2)) as sqlStatement([statement]);
-- clean up old deadlocks
DECLARE @limit BIGINT
SELECT DISTINCT TOP (500) @limit = DeadlockId
FROM ExtendedDeadlocks
ORDER BY DeadlockId DESC;
DELETE ExtendedDeadlocks
WHERE DeadlockId < @limit;
COMMIT
GO
Activating the Procedure
ALTER QUEUE dbo.LogDeadlocksQueueWITH ACTIVATION
( STATUS =ON,
PROCEDURE_NAME = dbo.ProcessDeadlockMessage,
MAX_QUEUE_READERS =1,
EXECUTEAS SELF
);
GO
ALTER QUEUE dbo.LogDeadlocksQueue
WITH ACTIVATION
( STATUS = ON,
PROCEDURE_NAME = dbo.ProcessDeadlockMessage,
MAX_QUEUE_READERS = 1,
EXECUTE AS SELF
);
GO
Clean Up
And when you’re all done, this code will clean up this whole experiment.
use master;
if(db_id('DeadlockLogging')isnotnull)beginalterdatabase DeadlockLogging set single_user withrollbackimmediatedropdatabase DeadlockLogging
endifexists(select*from sys.server_event_notificationswhere name ='DeadlockLogging')DROP EVENT NOTIFICATION LogDeadlocks ON SERVER;
use master;
if (db_id('DeadlockLogging') is not null)
begin
alter database DeadlockLogging set single_user with rollback immediate
drop database DeadlockLogging
end
if exists (select * from sys.server_event_notifications where name = 'DeadlockLogging')
DROP EVENT NOTIFICATION LogDeadlocks ON SERVER;
We don’t use CLR assemblies in SQL Server. For us, programming in the database means that maybe “you’re doing it wrong”. But there have been rare circumstances where I’ve wondered about what the feature can do for us.
For example, creating a CLR assembly to do string processing for a one-time data migration might be preferable to writing regular SQL using SQL Server’s severely limited built-in functions that do string processing.
Deployment Issues
I’ve always dismissed CLR as part of any solution because the deployment story was too cumbersome. We enjoy some really nice automated deployment tools. To create an assembly, SQL Server needs to be able to access the dll. And all of a sudden our deployment tools need more than just a connection string, the tools now need to be able to place a file where SQL Server can see it… or so I thought.
Deploy Assemblies Using Bits
CREATE ASSEMBLY supports specifying a CLR assembly using bits, a bit stream that can be specified using regular T-SQL. The full method is described in Deploying CLR Database Objects. In practice, the CREATE ASSEMBLY statement looks something like:
CREATE ASSEMBLY [MyAssembly]
FROM 0x4D5A900003000000040000... -- truncated binary literal
WITH PERMISSION_SET = SAFE
This completely gets around the need for deployments to use the file system. I was unaware of this option until today.
Your Experience
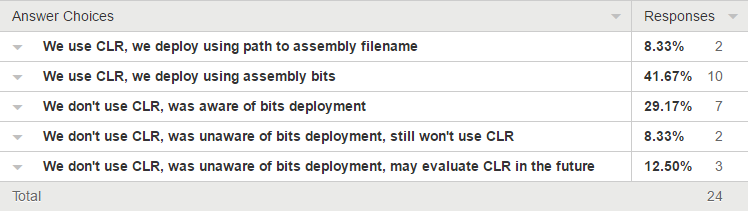
So what’s your experience? My mistaken assumptions kept me from evaluating CLR properly. I wonder if anyone is in the same position I was in and I wonder if this accounts for the low adoption in general of CLR in SQL Server. Answer this survey, Which option best describes you?
I recently learned that when combining multiple operators in a SQL expression, AND has a higher precedence than OR but & has the same precedence as |. I expected the precedence rules for the logical operators to be consistent with the bitwise operators.
Even Stephen Sondheim seemed to struggle with this.
I have a book on my shelf called Practical C Programming published by O’Reilly (the cow book) by Steve Oualline. I still love it today because although I don’t code in C any longer, the book remains a great example of good technical writing.
That book has some relevance to SQL today. Instead of memorizing the full list of operators and their precedence, Steve gives a practical subset:
Earlier this week I asked people to help me out prioritizing a list of issues. I was surprised by the number of people who participated. I think I missed an opportunity to crowd-source a large part of my job by including my real issues.
Results
Thanks for participating. After the results started coming in, I realized that my question was a bit ambiguous. Does first priority mean tackle an issue first? Or does a higher numbered issue mean a higher priority? I clarified the question and took that into account for entries that picked sproc naming conventions as top priority.
The results were cool. I expected a variety of answers but I found that most people’s priorities lined up pretty nicely.
For example, even though I wrote a list of issues all with different severity, there were three issues that stood out as most critical: Corrupted databases, a SQL injection vulnerability and No automated backups. Keeping statistics up to date seemed to be the most important non-critical issue.
But there is one issue that I thought had a lot of variety, index fragmentation. I personally placed this one second last. I got a friend to take the survey and I got to hear him explain his choices. He wanted to tackle index fragmentation early because it’s so easily fixable. “It’s low hanging fruit right? Just fix it and move on.”
My friend also pointed out that this technique would work well as an interview technique. Putting priorities in an order is important but even better is that it invites so much discussion about the reasons behind the order.
Speaking of which, go check out Chuck Rummel’s submission. He wins the prize for most thorough comment on my blog.
My Priorities
Here they are:
Corrupted database – serving data is what databases are supposed to do
No automated backups – protect that data from disasters
A SQL injection vulnerability – protect the data from unauthorized users
Stale statistics – serve data efficiently
Cursors – a common cause of performance issues, but I’d want to be reactive
GUID identifiers – meh
NOLOCK hints – meh
Developers use a mix of parameterized SQL and stored procedures – It’s not a performance concern for me
“One thing at a time / And that done well / Is a very good thing / As any can tell”
But life isn’t always that easy is it? I spend a lot of my workday juggling priorities. And I want to compare what I think to others. So I wrote a survey which explores the importance people place on different SQL Server issues. It’s easy to say avoid redundant indexes. But does it follow that it’s more important to clean up redundant indexes before rewriting cursors?
The List
Prioritize this list from greatest concern to least. So if an item appears above another item, then you would typically tackle that issue first.
Corrupted database
A SQL injection vulnerability
Stale statistics
Fragmented indexes
Developers use a mix of parameterized SQL and stored procedures
There’s always some anxiety when throwing a party. Wondering whether it will be a smash. Well I had nothing to worry about with the twenty bloggers who participated last week. You guys hit it out of the park!
The Round Up
Let’s get to it:
1. Rob Farley (@rob_farley) SQL Server 2016 Temporal Table Query Plan Behaviour
Rob digs into the query optimizer to highlight an interesting plan choice when temporal tables are involved. So extra care is needed when indexing and testing features that use temporal tables. What I Thought: I really enjoy Rob’s posts that digs into query plans and the optimizer in general.
Did you know that Rob has participated in every single T-SQL Tuesday? Even the rotten months when there’s like only three participants. Rob’s one of them.
2. Ginger Grant (@DesertIsleSQL) Creating R Code to run on SQL Server 2016
Ginger writes about how to get started coding with the R language. What I Thought: If you want to do the kind of analysis that R enables then bookmark her website! Her blog is becoming a real resource when it comes to working with R and SQL Server.
3. Ewald Cress (@sqlOnIce) Unsung SQLOS: the 2016 SOS_RWLock
Have you ever had to troubleshoot spinlock bottlenecks? You have my sympathies. Spinlocks are meant to be internal to SQL Server, something that Microsoft worries about. Ewald writes about new SOS_RWLOCK improvements. What I Thought: Do you like talks by Bob Ward? Do you like to dig into SQL Server’s internals? Does inspecting SQL Server debuggers and callstacks sound like a fun evening? This post is for you.
4. Russ Thomas (@SQLJudo) When the Memory is All Gone
Russ hasn’t posted to his blog recently because he’s been busy creating In-Memory OLTP courseware. So I’m glad that Russ is taking a break from that, returning to blogging and writing about … In-Memory OLTP. Specifically What I Thought: I like Russ’s style. He has to keep things professional and respectable for Pluralsight, but on his own blog he gets to talk about sandwiches, ulcers and tempdb.
5. Guy Glanster (@guy_glantser) We Must Wait for SP1 before Upgrading to SQL Server 2016
To be clear, Guy talks about why the wait-for-sp1 advice doesn’t apply. What I Thought: One sentence Guy wrote struck a chord with me: “I have never agreed with this claim, but in my first years as a DBA I didn’t have enough experience and confidence to claim otherwise, so I just assumed those people know what they’re talking about.” Wow, I’ve recognize that feeling. All I can say is that when you get past that feeling. That’s a really really good sign.
6. Patrick Keisler (@patrickkeisler) SQL Server 2016 Launch Discovery Day (aka Hackathon)
Patrick gives a recap on a SQL Server hackathon called “SQL Server 2016 Launch Discovery Day”. What I Thought: Wow, read the whole post, but if you can’t, at least check out the challenges and the scoring criteria. For example, the first challenge is to answer “From how far away do attendees travel to SQL Saturday? Are there any geographic trends to the distances traveled”. How would you approach this?”
7. Justin Goodwin (@SQL_Jgood) Use the Query Store In SQL Server 2016 to Improve HammerDB Performance
Justin describes query regressions he found in benchmark workloads when run against SQL Server 2014 and SQL Server 2016. Then, in 2016, he shows how to use Query Store to fix it! What I Thought: Fantastic post. And probably the best organized post of the month.
8. Kenneth Fisher (@sqlstudent144) Comparing two query plans
My friend Ken introduces the SSMS feature of comparing query plans. What I Thought: I have to admit that after reading his post I tried the feature out last Tuesday. I’ve since found myself using the feature a few times since. It’s a valuable tool for database developers. Thanks Ken!
9. Andy Mallon (@Amtwo) COMPRESS()ing LOB data
Andy wrote about new functions COMPRESS and DECOMPRESS which do that using the gzip algorithm. Andy gives an example of how you would use COMPRESS and what situations would make best use of this feature. What I Thought: I did not know about this. It’s a feature that I will use (once we adopt 2016).
10. Erik Darling (Erik Darling) Availability Groups, Direct Seeding and You
Erik introduces direct seeding for Availability Groups. Direct seeding lets DBAs avoid a step when launching a new replica. What I Thought: Apparently if you’re a DBA this is a CoolThing™. I kind of lost my taste for replication solutions – specifically transactional replication on flaky networks – in 2004. It’s nice to see that eleven years later, Microsoft is still working on making it easier to “move data from here to there”. (On the sincerity-sarcasm meter, that lies somewhere in the middle)
11. Deb Melkin (@dgmelkin) Temporal Tables
Temporal tables – not to be confused with temp tables – are the subject of Deb’s post. Earlier Rob Farley warned us to be careful about indexes on temporal tables. In Deb’s post, we’re warned about the precision of datetime2 columns in temporal tables. What I Thought: Thanks for writing Deb, I like your perspective and how you walk us through your thinking. Very compelling.
12. Chrissy LeMaire (@cl) So Why is sp_help_revlogin Still a Thing?
Chrissy Lemaire, Powershell MVP writes about how it’s still hard to migrate logins using only SQL Server. However there’s an easy solution using powershell. What I Thought: Chrissy is one of the bloggers who used my “It’s 2016, why is X still a thing?” writing prompt. Chrissy also points out how rapidly powershell is growing to better support DBAs. It turns into a very exciting story.
13. Aaron Bertrand (@AaronBertrand) This Weird Trick Still Missing From SQL Server 2016
Fellow Canadian and all around good guy Aaron also used the “It’s 2016, why is X still (not) a thing?” format. As developers, we’d like a way to use Developer edition to be able to deploy to Standard edition confidently without worry that we’ve accidentally used some feature only available in Enterprise Edition. What I Thought: Aaron’s absolutely right and I’ve been burned by this missing feature in the past. He links to two connect items and asks us to vote on them and leave business impact comments. I encourage you to do that too.
14. Robert Pearl (@PearlKnows) It’s SQL Server 2016 – stupid
Robert writes about SQL Server 2016 launch activities and three features he’s excited about, temporal tables, query store and better default tempdb configuration. What I Thought: It appears that NYC was the place to be when SQL Server 2016 launched. Maybe I’ll keep my calendar clear for SQL Server 2018.
15. Steve Jones (@way0utwest) Row Level Security
Row Level Security is Steve’s topic. He describes what it is, how it’s used and how he’ll never have to implement that feature from scratch again. What I Thought: Steve is optimistic about the feature and I am too. I think I was first introduced (in a way) to the idea behind the feature when I tried to look at sys.procedure definitions as a data reader.
16. Lori Edwards (@loriedwards) It’s 2016
Lori’s writes a good introduction to temporal tables. What I Thought: You know how when you visit documentation on a SQL Server keyword or function, you have to scroll to the bottom of the page to see an example? Not so with Lori’s introduction, her examples are up front and excellent.
17. Mike Fal (@Mike_Fal) SQL 2016 Direct Seeding
Mike Fal is the second one to mention direct seeding for Availability Groups. Nice! This promises to be a good feature for DBAs. What I Thought: In Erik’s post, he mentioned the lack of SSMS support. And so he pointed to a connect item about it. Mike Fal recognizing the issue tackled it with powershell. Good job.
18. Taiob Ali (@SqlWorldWide) JSON Support in SQL 2016
New JSON support! I was glad that someone wrote about it. And Taiob’s not just a JSON user. His workplace uses MongoDB as well. What I Thought: Thanks Taiob, At first I noticed your website’s domain: “SQLWorldWide” and wondered if you chose that name based on Microsoft’s new sample database World Wide Importers, but then I noticed you’ve been blogging for a while. If you know SQL Server and want to know what JSON is all about, this post is for you. If you’re a developer who uses JSON and want to know how to incorporate it into a SQL Server solution, this post is for you too.
19. Kennie Nybo Pontoppidan (@KennieNP) Temporal Tables are Just System History Tables (For Now)
Kennie writes about temporal tables. Wow, this seems to be a popular feature this year. He explains how relevant this feature is when compared with more traditional ways to implement type 2 history tables (slowly changing dimensions). What I Thought: Kennie mentions watching Chris Date and warehouse scenarios, so it’s nice to have the perspective of someone familiar with relational theory and also with data warehouses.
20. Riley Major (@RileyMajor) Let me count the ways…
Riley: I’d like a numbers table please Microsoft: SQL Azure Features? You got it. Riley: No, I said I’d like a… Microsoft: MORE AZURE COMING UP!
Thanks again everyone. Have a wonderful summer and a wonderful 2016!
So today is the last Tuesday in May which means that next Tuesday is the first Tuesday in June. On that day, you can expect me to invite all SQL bloggers to participate in June’s T-SQL Tuesday. So I’m thinking about my invite post: What will be the topic? What illustration will I include?
The T-SQL Tuesday Logo
When thinking about an illustration to include, I began to look more closely at the T-SQL Tuesday logo:
The logo includes a cylinder which is the standard way to represent a database (did you ever wonder why?). That’s what ties “T-SQL” to the logo.
But I want to point out something that not a lot of people notice. If you look really closely, you can see that the grid is actually a calendar for some month and the second Tuesday is highlighted. And that’s what ties “Tuesday” to the logo. Here, I’ll blow it up a bit:
But the resolution makes it hard to read or notice so as an exercise (and for my invite post illustration), I recreated the logo:
Another Take on the Logo
I happen to sit near some really cool graphics designers. And after some discussions about what makes a good logo, I came up with
Now don’t get too excited, it’s definitely not Machanic-approved. And I won’t be using this logo, it’s just an exercise.
But here are some of my thoughts.
It gets away from gradients which is a recent trend in logos and I keep it as uncomplicated as possible.
I stuck with blue (or Cyan actually). Microsoft seems to do that with Azure for example and there’s no sense in changing that.
I dropped the tie with Tuesday. When I think of T-SQL Tuesday, I think of databases and blogging, not the day of the week.
It’s meant to remind you of ERDs. Join diagrams are such a visual thing already and they’re closer to what we deal with on a day to day basis rather than the stereotypical cylinder.