


We encountered a CPU issue which took over a month to understand and fix. Since then, it’s been another couple months and so I think it may be time for a debrief.
The cause was identified as a growing number of ghost records that SQL Server would not clean up no matter what. Our fix was ultimately to restart SQL Server.

Symptoms and Data Collection
Here’s what we found.
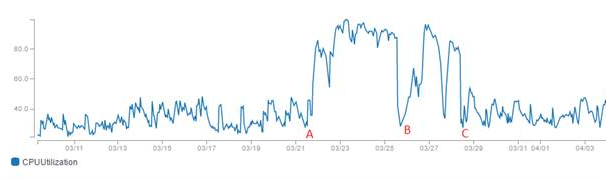
- At time marked ‘A’ on the graph, we noticed that CPU increased dramatically. It was hard not to notice.
- We used sp_whoisactive to identify a frequent query that was taking a large amount of CPU. That query had never been a problem before. It was a select against a queue table – a table whose purpose was to store data for an implementation of a work queue. This table had a lot of churn: many INSERTS and DELETES. But it was small, never more than 100 rows.
- So next, we ran the query manually in Management Studio.
SET STATISTICS IO, TIME ONgave us a surprise. A simple COUNT(*) of the table told us there were 30 rows in the table, but reading it took 800K logical page reads! - What pages could it be reading? It’s impossible for a table to be that fragmented, it would mean less than one row per page. To look at the physical stats we ran:
select sum(record_count) as records, sum(ghost_record_count) as ghost_records, sum(version_ghost_record_count) as version_ghost_records from sys.dm_db_index_physical_stats(db_id(), object_id('<table_name>'), default, default, 'detailed') where index_id = 1 and index_level = 0
And that gave us these results:

Interesting. The ghost records that remain are version_ghost_records, not ghost_records. Which sounds like we’re using some sort of snapshot isolation (which we’re not), or online reindexing (which we are), or something else that uses row versions. - Over time, those version_ghost_records would constantly accumulate. This ghost record accumulation was also present in all other tables, but it didn’t hurt as much as the queue table which had the most frequent deletes.

Mitigation – Rebuild Indexes
Does an index rebuild clean these up? In this case, yes. An index rebuild reduced the number of version ghost records for the table. At the time marked ‘B’ in the timeline, we saw that an index rebuild cleaned up these records and restored performance. But only temporarily. The version_ghost_records continued to accumulate gradually.
At time ‘C’ in the timeline, we created a job that ran every 15 minutes to rebuild the index. This restored performance to acceptable levels.
More investigation online
Kendra Little – Why Is My Transaction Log Growing In My Availability Group?
This is a great video. Kendra describes a similar problem. Long running queries on secondary replicas can impact the primary server in an Availability Group (AG). But we found no long running queries on any replica. We looked using sp_whoisactive and DBCC OPENTRAN. We didn’t see any open transactions anywhere.
Amit Banerjee – Chasing the Ghost Cleanup in an Availability Group
Amit also mentions that log truncation would be prevented in the case of a long-running query on a replica. However, in our case, log truncation was occurring.
Uwe Ricken – Read Committed Snapshot Isolation and high number of version_ghost_record_count
Uwe Ricken also blogged recently about a growing number of version_ghost_records. He talked about looking for open transactions that use one of the snapshot isolation levels. Unfortunately it didn’t apply to our case.
Bitemo Erik Gergely – A very slow SQL Server
Another example of a long running query keeping version_ghost_records around.
dba.stackexchange – GHOST_CLEANUP Lots of IO and CPU Usage
This stackexchange question also describes a problem with lots of CPU and an inefficient, ineffective ghost cleanup task for databases in an AG. There’s an accepted answer there, but it’s not really a solution.
Calling Microsoft Support
So we called Microsoft support. We didn’t really get anywhere. We spoke with many people over a month. We generated memory dumps, PSSDiag sessions and we conducted a couple screen sharing sessions. Everyone was equally stumped.
After much time and many diagnostic experiments. Here’s what we did find.
- Availability Groups with readable secondaries are necessary (but not sufficient) to see the problem. This is where the version_ghost_records come from in the first place. Readable secondaries make use of the version store.
- We ran an extended event histogram on the ghost_cleanup event. There was a ridiculous amount of events. Like millions per minute, but they weren’t actually cleaning up anything:
CREATE EVENT SESSION ghostbusters ON SERVER ADD EVENT sqlserver.ghost_cleanup( ACTION( sqlserver.database_id ) ) ADD TARGET package0.histogram( SET filtering_event_name=N'sqlserver.ghost_cleanup', source=N'sqlserver.database_id' )
- Microsoft let me down. They couldn’t figure out what was wrong. Each new person on the case had to be convinced that there were no open transactions. They couldn’t reproduce our problem. And on our server, we couldn’t avoid the problem.
Resolution
Ultimately the time came for an unrelated maintenance task. We had to do a rolling upgrade for some hardware driver update. We manually failed over the Availability Group and after that, no more problem!
It’s satisfying and not satisfying. Satisfying because the problem went away for us and we haven’t seen it since. After the amount of time I spent on this, I’m happy to leave this problem in the past.
But it’s not satisfying because we didn’t crack the mystery. And restarting SQL Server is an extreme solution for a problem associated with an “Always On” feature.
If you’re in the same boat as I was, go through the links in this post. Understand your environment. Look for long running queries on all replicas. And when you’ve exhausted other solutions, mitigate with frequent index rebuilds and go ahead and restart SQL Server when you can.

Rebuilding an index also updates that index’s statistics. Can the problem also be mitigated by updating statistics alone (without rebuilding the index)?
Comment by Bill — August 7, 2017 @ 9:41 am
This reminds me of a similar (but….also different) issue we had at one of my prior jobs. There, we were running 2008 with mirroring, and the ghost cleanup would just stop doing any work. We wouldn’t have performance issues, it would just stop cleaning up ghost records. Then, when we did a restart/failover the ghost cleanup would “wake up” and start doing it’s thing. We’d often see a CPU jump after patching/reboots as the ghost cleanup actually cleaned up.
In our case, CPU didn’t jump high enough that it caused us problems, so we never pressed hard enough to get to the root cause. But I wonder if the same ghost cleanup issue we had in 2008 is just rearing it’s head differently (and more aggressively) with AGs.
Comment by Andy Mallon — August 7, 2017 @ 9:44 am
Does trace flag 671 help in this situation?
Comment by Praveen — August 7, 2017 @ 10:12 am
So, we had the same problem with SQL not cleaning up the ghost records. Our database expanded by 3.5TB before we realized what it was. After some digging I found a connect item stating it was a known bug in SQL server 2008 SP3 and prior. Applying SP4 and restarting the instance resolved the issue for us. We then spent 36 hours migrating all the data to new data files to bring our database back to its actual size. We have not had the issue since applying SP4.
Comment by John Couch — August 7, 2017 @ 12:28 pm
As a follow-up, ours was tied to the deletion of LOB data. Forgot to mention that. Here was an article on it: https://support.microsoft.com/en-au/help/2967240/fix-cannot-reclaim-unused-space-by-using-shrink-operation-in-the-table
Comment by John Couch — August 7, 2017 @ 12:32 pm
@Bill – Statistics was not enough. The index needed to be rebuilt.
@Andy Mallon – Wow. Unexplained issues are the worst. I wonder if it was the same issue. Who knows.
@Praveen – Maybe, I don’t know much about trace flag 671. A quick search tells me the flag disables deferred deallocation. As a server level setting, I would have been reluctant to try it. Microsoft support didn’t even suggest it.
@John Couch – Wow. We are running 2014 SP1 (which is after 2014 CU2 mentioned in the fix you linked to). If it is the same issue, then it’s a regression or something. In any case, it’s an internal thing that I expected Microsoft to handle. Since SQL Server is not open-source, there’s only so much that can be expected of us when there’s an internals bug. I know I get really frustrated with issues that are out of my control. I’m sure you do too.
Comment by Michael J. Swart — August 7, 2017 @ 3:40 pm
“And restarting SQL Server is an extreme solution for a problem associated with an “Always On” feature.”
Well, yes, that’s true. In this case, it appears clearly related to the Always On feature itself. On the other hand, having Always On features configured enabled you to at least restart that server without business impact.
PS: In case someone else were to run into this issue, now that we know it’s resolved by rebooting, it would be good to check logs all the way back to the last reboot to see if anything happened in the internals that caused the ghost versions to remain.
Comment by Speedbird186 — August 7, 2017 @ 4:35 pm
@Speedbird186 – I definitely have high expectations for Microsoft’s availability features. But I feel entitled to them not only because of the price tag on SQL Server, but also because I look at the availability features of some cloud offerings and other distributed technologies and I want something robust that works.
Checking the logs during a previous server start means we’re hoping for two things: (1) Whatever happened to cause the problem occurred during server start. And (2) That something gets logged then that can give a meaningful clue. But (spoilers) we had those logs this time and in our case, we didn’t find anything that helped.
Comment by Michael J. Swart — August 7, 2017 @ 9:53 pm
Hi.
I think that you have been dealing with a similar problem to the one analized by Runanu in this blog post regarding Service Broker queues.
http://rusanu.com/2010/03/09/dealing-with-large-queues/
Actually, you are using that table as a Queue and is the same pattern that the internal tables used by Service Broker.
His case was even worst because in 2005 you could not rebuild a queue.
Comment by Jorge — August 8, 2017 @ 3:41 am
@Jorge – That’s a great article. And I wonder if it is in fact the same thing. In Rusanu’s case, when he finally was able to rebuild his queue table, his problem went away permanently.
In the future, it’s my hope to change our application so that we no longer use queues with messages persisted in SQL Server, but to actually use a cloud-based queue service.
Comment by Michael J. Swart — August 8, 2017 @ 8:53 am
Great article, so glad you published this.
A colleague found it this weekend, after we spent all day Friday chasing high CPU/TPS. Seems like we had exactly what you describe: a very small queue table (supports NServiceBus) with inordinately slow query time and high logical reads, e.g. SELECT TOP 1 from 5-row table took over a sec and 16K logical reads. The table/db in question is in an AG where we do have a readable secondary.
By the afternoon we tried drop/recreate table and rebuilding indexes. Initially both techniques seemed to help but only briefly. At some point late in the day the problem seemed to clear up and we’ve been fine since. We did NOT failover the AG. It is possible, likely even, that the application load changed.
I’m now working with the dm_db_index_physical_stats query. DETAILED seems pretty heavy/slow, trying to see if we can get by with SAMPLE. All with goal of creating a job that helps keep us at your point C if it ever again becomes necessary.
Comment by Mike Good — August 28, 2017 @ 10:48 am
Update – we believe the most likely cause of our situation last week was an end-user querying data on the readable secondary. We can completely reproduce all the symptoms (including high CPU, high TPS, high logical reads) just by selecting data from our readable secondary (albeit by holding open a transaction on the secondary to exacerbate things). Now we’re reconsidering use of readable secondary for this specific case.
Comment by Mike Good — August 28, 2017 @ 4:51 pm
Is this a heap table?
Because here is similar case : http://sqlblog.com/blogs/rob_farley/archive/2017/03/14/sql-wtf-for-t-sql-tuesday-88.aspx
Comment by Sabi — September 12, 2017 @ 10:35 am
@Sabi, It was not a heap table. There was a clustered index on it.
Comment by Michael J. Swart — September 12, 2017 @ 11:04 am
Maybe the Ghost Cleanup Task failed for that database entirely through some bug. Maybe anything that reboots the database restarts the task and mitigates the issue. I wonder if a failing Ghost Cleanup Task would generate any error log output.
Comment by tobi — September 12, 2017 @ 2:08 pm
@tobi Those were my thoughts. It may be worth exploring if (God forbid) I ever encounter the problem again.
I do know that there was no error log output that mentioned anything about any ghost cleanup problems.
Comment by Michael J. Swart — September 12, 2017 @ 2:39 pm
So helpful, Michael – thanks.
Paul Randal wrote, way back in 2010, (https://www.sqlskills.com/blogs/paul/turning-off-the-ghost-cleanup-task-for-a-performance-gain/) about REORGANIZE or REBUILD solving the problem proactively, so as to not be dependent upon the background cleanup. Not being an internals chap, have you found that reorganize is equally effective? I ask because we have customers on Standard Edition where reorg would be our go-to for Q-type tables, and for many of our cache-type tables where somewhat frequent delete-from activity occurs on large volumes that can equally overwhelm the ghost-cleanup. Thanks again.
Comment by SAinCA — November 13, 2017 @ 8:52 pm
Hi SA in CA,
Check out the section, “Mitigation – Rebuild Indexes” We found that REBUILD only held the bad behavior we were seeing at bay.
My guess is that the REORGANIZE behavior would be less effective for what we were experiencing.
I want to reiterate that the behavior we were seeing was buggy behavior. Behavior that was hard to reproduce and went away with a failover.
Once the buggy behavior went away, ghost-cleanup worked nicely again.
So I wouldn’t make any long-term configuration choices based on this buggy behavior. REBUILD or REORGANIZE your indexes based on what you need from your databases, but it’s probably not wise to use it to shore up the ghost cleanup task.
Comment by Michael J. Swart — November 14, 2017 @ 2:51 pm
I know this in a late response to this, but I’ve been having issues with 2 client having issues with either the version store growing and not shrinking, or the version_ghost_record_count remaining very high. In both cases I’v been able to show conclusively that there were stale connections that had done a BEGIN TRAN that were causing the problems. Also in both cases the databases were in Read Committed Snapshot Isolation (RCSI). The fact that the problem went away after the AG Failover is revealing in two ways:
1) The AG failover would have closed any stale connections which may have been causing your problems.
2) SQL uses a form of RCSI to ensure consistency, particularly related to Readable Secondaries, so I’ll be doing some tests around this.
Interestingly in the latest incident, there were two databases, with only one showing issues, and the stale connection was showing as connected to the “other” database. As soon as we killed the stale connection, the ghost version records started going away.
Comment by Leo Miller — November 1, 2018 @ 11:04 pm
I’m glad that worked for you Leo, I’ve learned that stale connections were not the issue in my case.
When I wrote that “We didn’t see any open transactions anywhere” it was actually more than that. We didn’t see any long-lasting connections anywhere either.
Comment by Michael J. Swart — November 2, 2018 @ 8:32 am
Hey There!
I know that the issue is aged but I think that the comment maybe helpful for someone like me in anytime, my problem is in AG environment and by setting [NO] option for [Readable Secondary] of Secondary Nodes, the Problem Solved
Comment by Arm — May 5, 2024 @ 2:10 am