


Takeaway: I explain how SQL Server is aware that inner joins are commutative and so the order of tables in your queries doesn’t matter.
Update Jan. 11, 2013: Please see my update at the end of this article where I qualify that statement (because it depends).
I want to explore a common question I get from people who are getting up to speed on this whole SQL thing. At one time or another, we’ve all wondered whether we get any performance improvements by varying the order that we join tables together (and by joins I mean inner joins).
The answer is no, so you can safely stop messing with the join order of your tables for performance reasons. So…

The point is that when SQL Server executes a query it explores query plans with different join orders, it then evaluates the estimated cost of each plan and picks the best one. It follows directly that changing the order of the tables in the from clause is not an effective optimization technique.
In other words, A JOIN B is equivalent to B JOIN A and SQL Server knows it. You can see this for yourself:
Showing that Joins are Commutative
The best way to demonstrate that is to come up with an example where SQL Server chooses a different join order for a query plan than the order specified in the query.
The Setup
First create tables A, B and C and populate them
use tempdb; create table A ( id int identity constraint PK_A primary key, value uniqueidentifier default newid() ); create table B ( id int identity constraint PK_B primary key, value uniqueidentifier default newid() ); create table C ( id int identity constraint PK_C primary key, value uniqueidentifier default newid() ); GO set nocount on; insert A default values; GO 100 insert B default values GO 500 insert C default values GO 1000 |
Query With Two Joins
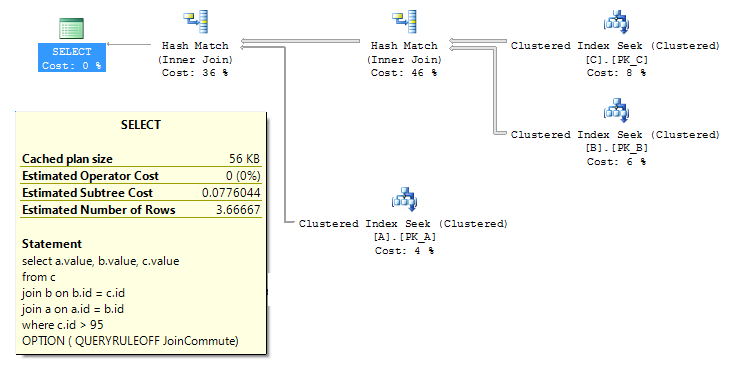
Check out the following query and query plan (with no query hints):
select a.value, b.value, c.value from c join b on b.id = c.id join a on a.id = b.id where c.id > 95 |

Notice that SQL Server has changed the join order from C-B-A to A-B-C because it’s better that way.
Same Query With Restricted Join Order
If you really want to, you can force the join order with the FORCE ORDER query hint. We’re basically telling the query optimizer to not explore plans with different join orders. The query optimizer uses different rules when exploring different plans to evaluate. One of the rules is called JoinCommute. We can actually turn it off using the undocumented query hint QUERYRULEOFF.
select a.value, b.value, c.value from c join b on b.id = c.id join a on a.id = b.id where c.id > 95 OPTION ( QUERYRULEOFF JoinCommute) |
And we see that turning off JoinCommute gives behavior and performance just like FORCE ORDER.
Kind of neat eh? Now when the next person asks you whether the join order makes any difference, you can confidently say no. And if that person is from Missouri (the “Show me” state) you can point them to this post.
Update: But Not Always
From the above, you could take it that equivalent queries with different join orders should have the same query plan. But it turns out that in some cases, equivalent queries (with different join orders) generate different plans if the query itself has many tables to join. In this case what’s happening is that SQL Server’s query optimizer chooses a plan that’s not optimal. It can do this if:
- While evaluating different plans, it found a Good Enough Plan and then stopped evaluating others. It’s rare, but sometimes what’s good enough for SQL Server is not good enough for you.
- While evaluating different plans, it Timed Out and stopped evaluating others. In this case SQL Server didn’t evaluate all the different join orders, it evaluated a fair number of them and picked the best one it found
Check out this example which extends my ABC example to ABCDEF:equivalent-queries different-plans.sql (Courtesy @BrentO). It shows equivalent queries which generate query plans with different costs.
It’s tempting to then throw this article out and resume caring about the join order. It’s tempting to place smallest tables or the tables with the most selective filters up front telling SQL Server: “You’re going to evaluate a variety of join orders, maybe not all of them, but at least evaluate this one.”
All I can say is that in my time with this stuff, I’ve never needed to care. I mean I’ve seen that it can make a difference with very complicated queries or views, but I’ve also always been able to find a more stable/standard/supported way to improve performance. Like making sure statistics and indexes are up to snuff. The practice of using temp tables to store intermediate results was suggested by Brent and has worked for me too. As a last resort, I might consider different join orders but like I said, I’ve never needed to yet.
One last note, Microsoft’s Conor Cunningham wrote a very relevant post on this topic: http://blogs.msdn.com/b/conor_cunningham_msft/archive/2009/12/10/conor-vs-does-join-order-matter.aspx. Again, thanks Brent Ozar for that link.

MAL!
Sadly, I can’t read any more of the post because I immediately start playing my Firefly DVDs. (sigh)
Comment by Brent Ozar — January 11, 2013 @ 9:21 am
Don’t be ridiculous, that’s the proper reaction to this post. When’s the last time you saw Jaynestown? (the episode where Jayne discovers he’s a folk hero on some planet). Probably too long ago that’s when.
Comment by Michael J. Swart — January 11, 2013 @ 9:28 am
Unfortunatly, it appears that LEFT JOINs are never reordered due to a bug… I posted this as a connect issue including repro: http://connect.microsoft.com/SQLServer/feedback/details/649688/sql-server-does-not-reorder-left-joins-even-if-cost-reducing
I think this is a major problem and I have felt its consequences.
Comment by tobi — January 12, 2013 @ 9:23 am
Hi tobi,
I’ve only tested on SQL 2012, but it appears that SQL Server is re-ordering LEFT JOINS. I ran your repro and then I ran it again with OPTION (FORCE ORDER) on each query. The plans are quite different. So it appears that SQL Server certainly is considering re-ordering left joins. Could you verify that behavior?
The thing you’re wondering about is why the plan for C *= S *= A *= H is not the same as the plan for C *= H *= A *= S. The idea is that if they’re semantically equivalent queries, then full optimization should come up with identical plans. I haven’t convinced myself that the queries in the repro are semantically equivalent.
Comment by Michael J. Swart — January 12, 2013 @ 4:04 pm
Michael after posts like this “my days of not taking you seriously are certainly coming to a middle.” But seriously…excellent post. I actually saw Jaynestown just last week. I’m working my way through the DVDs for the, oh, 15th time. Next up, “War Stories.”
Comment by Dale Burnett — January 13, 2013 @ 10:27 pm
I encountered a related problem on a query in which the order of 2 arguments in the WHERE clause changed the execution times by a factor of 1,000:
http://www.sqlservercentral.com/Forums/FindPost1089981.aspx
I never found a satisfactory answer to why this occurred, other than the fact that the generated plans varied based on the order of those 2 clauses. It seems that the query optimizer can generate different plans depending on the order of 2 arguments in a WHERE clause.
Likewise in your update (and recommended by Brent Ozar), dumping intermediate results from a complex query to a temp table resolved my problem of execution times that varied by 3 orders of magnitude!
Comment by Rich Mechaber — January 14, 2013 @ 8:46 am
[…] Joins are Commutative and SQL Server Knows it – Michael J. Swart (Blog|Twitter) […]
Pingback by Something for the Weekend - SQL Server Links 18/01/13 — January 18, 2013 @ 9:04 am
[…] 4. Joins are Commutative and SQL Server Knows it […]
Pingback by Friday Five - January 18, 2013 - The Microsoft MVP Award Program Blog - Site Home - MSDN Blogs — January 18, 2013 @ 4:17 pm
Would using a CTE be equivalent to “using temp tables to store intermediate results”?
Comment by Mark Freeman — March 18, 2013 @ 12:55 pm
Hi Mark,
No, under the covers CTEs are very much like subqueries. The goal behind the advice “use temp tables to store intermediate results” is to recognize that a query is so unweildly, that SQL Server’s query optimizer has a tough time finding an optimal plan in a decent amount of time. And by storing intermediate results, it may be better to give SQL Server a chance to tackle two simpler queries. Using temp tables this way shouldn’t be applied often and without testing. Because sometimes this technique does more harm than good.
Now for CTEs. If we use CTEs it may make the query easier to follow logically, but SQL Server’s query optimizer still tackles the whole thing as a single query. A query rewritten using a CTE may perform differently simply because a rewritten query is often a different query. But not for any reason you can count on.
Comment by Michael J. Swart — March 18, 2013 @ 2:39 pm
[…] read this all the way […]
Pingback by Office Hours Speed Round: Text Edition - Brent Ozar Unlimited® — July 29, 2022 @ 9:16 am