I don’t often talk much about what I do at my job, but I wanted to break that rule in this post.
I work for Desire2Learn, a Canadian company that (among many other things) provides e-learning solutions for Colleges and Universities. This week Microsoft announced that Desire2Learn won the Partner of the Year award for Worldwide Education.
“Microsoft is pleased to recognize Desire2Learn’s commitment to education customers within the Public Sector by awarding them Education Partner of the Year,” said Anthony Salcito, vice president of Worldwide Education at Microsoft. “The Desire2Learn® Learning Environment is a complete web-based suite of easy-to-use tools and functionality built exclusively on Microsoft Windows and SQL Server, plus integration with Live@edu. The scalability of their solution provides Desire2Learn with the ability to connect schools and organizations of all types, and to provide a borderless environment in which to teach and learn – today more than six million learners worldwide reap the benefits of Desire2Learn’s applications.”
I’m proud to be part of that team and I wish Desire2Learn a big congratulations. Way to go guys!!
When SQL Server Management Studio (SSMS) talks to the database engine it uses the same system objects, tables and views that are available for any other database client to use. (The same can’t be said for system stored procedures which use crazy system-only functions. I mean check out the definitions of any system view or procedure with sp_helptext)
Eavesdropping On SSMS
So we can actually watch SSMS talking to the database using Profiler. We can take a look “behind the curtains” so to speak.
Here are the profiler settings that I always use:
Default trace template
Application Name LIKE ‘Microsoft SQL Server Management Studio%’
Hostname = <my computer’s name>
This lets us see the queries that SSMS is sending to SQL Server. It’s a trick I use often to give me an idea of what system views and objects might be important when managing SQL Server. (And managing SQL Server includes automating management tasks). So now I want to show you some examples.
SSMS Things I Wonder About
Here’s a few things that I wonder about. They’re not necessarily important things on their own, but they’ll help me show how to use profiler to look inside SSMS.
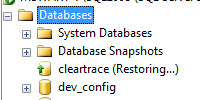
Thing 1: What’s that red down-arrow over a database user. It reminds me of a database that’s been brought “offline”, but I’ve never heard of an “offline” user.
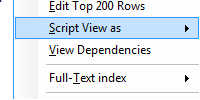
Thing 2: When scripting views, how does SSMS retrieve definitions?
Thing 3: I have a database that is restored, but without recovery. SSMS shows it with a green up-arrow and with appended text (Restoring …). How does it know which databases are in that state?
No Longer Wondering
So here’s what I found.
Question
What’s that red down-arrow over a database user?
Profiler Info
When I refreshed the Users node in Object Explorer, I saw this in profiler.
What this means
Unsurprisingly, the red arrow means user has no db access and it doesn’t mean disabled user. In other terms, SSMS is looking for a list of users and whether or not they have db access. DB Access here is determined by whether users have been granted (database_permissions.state is ‘G’ or ‘W’) permission to connect (database_pemissions.type=’CO’).
Books Online
I couldn't find links for the Users node in Object Explorer, but here’s the documentation for sys.database_permissions.
Question
When scripting views, how does SSMS retrieve definitions?
Profiler Info
When I scripted a view to clipboard, this is what I saw in profiler.
What this means
So in this case, SSMS is looking to sys.sql_modules for the definition of the stored procedure. That’s good and it’s what I expected. I was a little afraid that it would use sys.syscomments (which was so 2000). But I was surprised that it also uses a view called sys.system_sql_modules in case the procedure was a system one. I was unaware of that view.
Books Online
Point for Microsoft, they document how to script objects well.
Question
How does SSMS know which databases are in a Restoring state?
Profiler Info
When I refreshed the Databases node in Object Explorer, I saw this in profiler.
What this means
If you squint at the SQL – a highly effective method for understanding SQL – you'll see that we can determine the restore status of a database by looking at the state column of the table master.sys.databases. In this case, when state=1 the database is in the Restoring state. There was actually nothing too surprising here. In this case, SSMS's queries match my expectations.
Books Online
Kudos to Microsoft again. Here is their docs for sys.databases (with more information on that state table).
This Goes For Any Application
To satisfy curiosity, I’ve profiled lots of other database applications on my development machine and you can too.
If you’re a real keener, and you want a self-guided deep dive into SQL database internals. Try profiling Danny Gould’s Internals Viewer. It’s an eye opener.
So it’s been about half a year since Jen McCown invited SQL Bloggers to post their new years resolutions. I made mine and I’ve kept up with it, but I’m going to reassess that resolution now.
If you remember, my resolution was to blog once a week (with articles to go live every Wednesday at noon), keep to technical content, and include an illustration with each post. Check, check and check. My goal was to get 4 times as many readers than the previous year.
Well, I’m not quite there. Google Analytics tells me I’m at 3.3 times as many readers as the first half of 2010 … So what do I need to do to get to 4.0?
Some ideas that came to mind were:
I could post five or six times a month instead of four. Going for volume.
I could focus on plugging my site in other places.
I could participate in every meme monday, t-sql tuesday and un-sql friday out there.
But none of those are appealing. Those thoughts don’t light a fire under me. So I’m going to say “You know what? 3.3 is good enough“.
So what does light a fire under me?
Writing about SQL
Drawing stupid illustrations.
I’m Giving Up My New Year’s Resolution
So I’m giving up the goal of the resolution, but I’m not changing my blogging habits… At least not too much. You’ll notice this post still got posted on a Wednesday at noon.
In The End It Wasn’t About Readership
Besides, I’ve realized that it’s not really readership I was after, it was the commenters! (Commenters! Commenters! Commenters!). The lurkers can continue lurking, but I’d rather have 10 comments on a post than 10,000 page views. The feedback is really good to have and I’m happy with that.
And to other bloggers out there, I suspect that you feel the same. My guess is that you’d prefer ten new active readers versus ten thousand new passive readers.
An Illustration
So I’m breaking my own rules. This isn’t a technical post and the illustration here has nothing to do with the subject of this post. So why do I include an illustration of Wicket Baggins here?
Takeaway: I like to develop database stuff using rules of thumb. When two rules of thumb are at odds, what should I do? This post, I explore the advice: It depends with an example.
I first give the two rules of thumb:
Rule Of Thumb #1: Avoid Triggers
I don’t like triggers too much and I avoid them whenever possible. It’s just that they
hide so much that might go wrong,
They’re a huge source of frustration when debugging problem queries
They’re often a symptom of sloppy db design and
it’s a common mistake to write them using the assumption that the inserted virtual table contains a single row
Rule Of Thumb #2: Enforce Business Rules In The Database
It’s good to enforce business rules at the database:
Databases often outlive the applications that are built against it
It’s too difficult to enforce the rules in a single place only (e.g. the application). The effort needed to keep the data clean becomes unsustainable.
They can help development. It shouldn’t need saying that if foreign keys throw errors during development, don’t get rid of them! They’re doing their job!
The Example: No Overlapping Intervals
This is where the two rules of thumb collide! It’s because not all business rules are easy to implement. Take this example, the case of preventing overlapping intervals. It’s a common scenario. Some examples are seen
when scheduling resources (planes at a gate, weddings at a hall, meetings in rooms)
when enforcing one thing at a time (terms of a particular office, factory equipment status)
To restrict overlapping intervals, the usual business rule enforcement tricks don’t work:
They cannot be enforced easily with database table design (foreign keys don’t apply because the constraint applies to a single tableSee Comments).
They can’t be enforced easily with checks because a check constraint only enforces rules on values in a single record. But the overlapping interval restriction is a restriction based on two records.
And unique indexes can’t help either.
But the constraint we want to enforce could be implemented decently with a trigger. Consider this table that tracks what I call shifts:
USE tempdb
GO
CREATETABLE SHIFTS (
shiftId intidentityprimarykey,
beginTime datetime2 notnull,
endTime datetime2 notnull,
check(beginTime < endTime ))CREATEUNIQUEINDEX IX_SHIFTS
ON SHIFTS(beginTime)
INCLUDE(endTime)
GO
USE tempdb
GO
CREATE TABLE SHIFTS (
shiftId int identity primary key,
beginTime datetime2 not null,
endTime datetime2 not null,
check (beginTime < endTime )
)
CREATE UNIQUE INDEX IX_SHIFTS
ON SHIFTS(beginTime)
INCLUDE(endTime)
GO
We’ve already enforced that shifts go forward in time with a check and that no two shifts will start at the same time with a unique index. Here’s a trigger which will enforce that no two shifts overlap:
CREATETRIGGER t_NoOverlappingShifts
ON SHIFTS
AFTERUPDATE, INSERTASIFEXISTS(--next shift starts after this one endsSELECT1FROM inserted
CROSS APPLY (SELECTTOP1 beginTime
FROM SHIFTS
WHERE beginTime > inserted.beginTimeORDERBY beginTime ASC)AS NextShift(beginTime)WHERE NextShift.beginTime< inserted.endTime)BEGINRAISERROR('Error: Shifts cannot overlap.', 16, 1)ROLLBACKTRANSACTIONENDIFEXISTS(--previous shift ends before this one startsSELECT1FROM inserted
CROSS APPLY (SELECTTOP1 endTime
FROM SHIFTS
WHERE beginTime < inserted.beginTimeORDERBY beginTime DESC)AS PrevShift(endTime)WHERE PrevShift.endTime> inserted.beginTime)BEGINRAISERROR('Error: Shifts cannot overlap.', 16, 2)ROLLBACKTRANSACTIONEND
GO
CREATE TRIGGER t_NoOverlappingShifts
ON SHIFTS
AFTER UPDATE, INSERT
AS
IF EXISTS (
--next shift starts after this one ends
SELECT 1
FROM inserted
CROSS APPLY (
SELECT TOP 1 beginTime
FROM SHIFTS
WHERE beginTime > inserted.beginTime
ORDER BY beginTime ASC
) AS NextShift(beginTime)
WHERE NextShift.beginTime < inserted.endTime
)
BEGIN
RAISERROR ('Error: Shifts cannot overlap.', 16, 1)
ROLLBACK TRANSACTION
END
IF EXISTS (
--previous shift ends before this one starts
SELECT 1
FROM inserted
CROSS APPLY (
SELECT TOP 1 endTime
FROM SHIFTS
WHERE beginTime < inserted.beginTime
ORDER BY beginTime DESC
) AS PrevShift(endTime)
WHERE PrevShift.endTime > inserted.beginTime
)
BEGIN
RAISERROR ('Error: Shifts cannot overlap.', 16, 2)
ROLLBACK TRANSACTION
END
GO
The trigger performs decently, and it does its job, but it’s not suited for every situation (e.g. bulk load operations)
My Opinion
So I ask myself the question: Is it good to create the trigger in this case?. I’m going to say that this trigger is good and that the value of enforcing business rules here is better than avoiding triggers because
the trigger doesn’t have any “side effects”. What I mean is that besides sometimes failing, the data in the database won’t be different than if the trigger didn’t exist
the trigger handles inserts or updates of multiple rows correctly
this trigger is not a bandaid for sloppy database design (like those maintenance triggers that keep redundant data in synch)
But I’d like to hear what you think in the comments.
P.S. It occurs to me that maybe you don’t even have the same rules of thumb that I mentioned. So what do you think? triggers: good or bad?
Takeaway: Until recently, I was a huge T-SQL PIVOT fan. But the more I think about it, the more I realize that it’s probably better to pivot data anywhere else than to pivot data in SQL Server. I talk about easier and better alternatives to PIVOT. Remember PIVOT is a T-SQL command that was introduced in SQL Server 2005 that lets you return results as pivot tables or more commonly as cross tabulations.
SQL Server 2000 and Earlier
I remember the first time I came across the need for pivot tables. I knew what I needed the data to look like, but I didn’t know what they were called. It didn’t matter, PIVOT wasn’t yet a T-SQL keyword and I couldn’t make use of it any way.
I was asked to write a query that returned data about the number of widgets and their categories. That seems like no problem right? Except I was asked to return the data in a two dimensional grid (with widgets as rows and categories as columns). It was a perfect use case for PIVOT! Except that it wasn’t yet available and so I was forced to write something complicated in T-SQL that used subqueries, CASE statements and other crazy stuff.
The resulting query was at least 100 lines. It looked complicated but it did the trick. I was actually congratulated on my SQL skillz (although in hindsight I shouldn’t have been).
But it got me to thinking. Why was that so hard? I used to think that any reasonable English question can be translated into simple SQL. But here was a big fat hairy counter-example. I eventually came up with an answer: It’s because the requested data has information about different sets of data in the same row.
SQL Server 2005 and Later
Fast forward a few years. I was learning about all the new stuff that SQL Server 2005 could do. And I came across the new PIVOT keyword. I knew immediately what it could do for me. I knew immediately how it was used. And I used it when the results called for it. I never remembered the syntax because I knew I could always look it up.
Eventually I gained a reputation as a SQL know-it-all (whether I deserved it or not) and I started fielding database questions. If any colleagues were struggling to return a cross-table, it was easy to recognize what they were doing and easier to point them to the online docs for PIVOT.
Or Just Let The App Deal With It
But I realized recently that it’s really not necessary. At the database level, I probably don’t have to pivot this. I can ask the question: Do I really need to deliver the data that way – pre-pivoted? Heck No! I can delegate that stuff. It’s actually a lot easier to pivot this data almost anywhere else besides SQL Server.
So in essence I’m giving myself (and you!) permission to forget something: T-SQL’s PIVOT syntax.
Pivot Inside Excel
Say the data is a one-time-only query and you want to include a cross table in a spreadsheet or email. Well Excel’s pivot feature turns out to be dead simple. This pivot functionality is also found in Open Office’s Calc and any other spreadsheet application built this century. Just a couple extra tips:
Using the “format as table” feature can save yourself a couple clicks.
Find the “Create Pivot Table” feature under the Insert tab.
If you’re still having any trouble, I’m sure there’s tons more help here.
Pivot Inside a .Net App
Okay, so say you’re writing some C# and you have a DataTable that you wish were more pivot-y. Ask and ye shall receive:
DataTable Pivot( DataTable dt, DataColumn pivotColumn, DataColumn pivotValue ){// find primary key columns //(i.e. everything but pivot column and pivot value)
DataTable temp = dt.Copy();
temp.Columns.Remove( pivotColumn.ColumnName);
temp.Columns.Remove( pivotValue.ColumnName);string[] pkColumnNames = temp.Columns.Cast<DataColumn>().Select( c => c.ColumnName).ToArray();// prep results table
DataTable result = temp.DefaultView.ToTable(true, pkColumnNames).Copy();
result.PrimaryKey= result.Columns.Cast<DataColumn>().ToArray();
dt.AsEnumerable().Select(r => r[pivotColumn.ColumnName].ToString()).Distinct().ToList().ForEach(c => result.Columns.Add(c, pivotValue.DataType));// load itforeach( DataRow row in dt.Rows){// find row to update
DataRow aggRow = result.Rows.Find(
pkColumnNames
.Select( c => row[c]).ToArray());// the aggregate used here is LATEST // adjust the next line if you want (SUM, MAX, etc...)
aggRow[row[pivotColumn.ColumnName].ToString()]= row[pivotValue.ColumnName];}return result;}
DataTable Pivot( DataTable dt, DataColumn pivotColumn, DataColumn pivotValue ) {
// find primary key columns
//(i.e. everything but pivot column and pivot value)
DataTable temp = dt.Copy();
temp.Columns.Remove( pivotColumn.ColumnName );
temp.Columns.Remove( pivotValue.ColumnName );
string[] pkColumnNames = temp.Columns.Cast<DataColumn>()
.Select( c => c.ColumnName )
.ToArray();
// prep results table
DataTable result = temp.DefaultView.ToTable(true, pkColumnNames).Copy();
result.PrimaryKey = result.Columns.Cast<DataColumn>().ToArray();
dt.AsEnumerable()
.Select(r => r[pivotColumn.ColumnName].ToString())
.Distinct().ToList()
.ForEach (c => result.Columns.Add(c, pivotValue.DataType));
// load it
foreach( DataRow row in dt.Rows ) {
// find row to update
DataRow aggRow = result.Rows.Find(
pkColumnNames
.Select( c => row[c] )
.ToArray() );
// the aggregate used here is LATEST
// adjust the next line if you want (SUM, MAX, etc...)
aggRow[row[pivotColumn.ColumnName].ToString()] = row[pivotValue.ColumnName];
}
return result;
}
If you know the shape of your data ahead of time, you could have coded this more easily by hard coding column names. But what I’ve given here is a general procedure (It works on most test cases. Error handling and extra testing are left as an exercise for the reader 🙂 ).
Pivot Inside Other B.I. Clients
Most other clients I can think of have even easier pivot features:
Reporting Service’s matrix control is a pivot table.
Analysis Service’s cubes are nothing but a multi-dimensional pivot tables.
Other Business Intelligence software is all over this. If your B.I. software can’t do cross-tables or pivot tables, I would ask for your money back.
You don’t need T-SQL’s PIVOT table at all. Forget that stuff…
… Except When You Do Need T-SQL’s PIVOT
Okay, maybe I’m a bit over-zealous there. Here are some reasons why you might want to use T-SQL’s PIVOT tables. They’re not great reasons but I present them any way. You’ll need to know this stuff:
when studying for certifications, interviews or other tests,
when the application or data destination you’re working with is not suited to pivoting (although nothing comes to mind). Your choice is then PIVOT using T-SQL or not at all.
when the data’s destination is the SSMS results pane. That’s fair.
when you don’t have control over the app, or the app is too difficult to modify and it’s expecting a cross-table for data.
So for the most part, you can forget about PIVOT syntax. Next week maybe I’ll talk about remembering the syntax for the MERGE statement. In my opinion, SQL’s MERGE statement is a statement worth remembering, but that’s another story.
No, I’m not talking about the friendly Mehta family a few doors down. I’m talking about the prefix Meta. In particular I’ve noticed a few SQL Blog post aggregator sites and I wanted to aggregate the aggregators, review the reviews and round up the round-ups.
But How Do I Use This Post?
I wrote this post because a friend of mine wanted to keep up with what’s new in the industry. When I showed him my list of RSS feeds, it was a bit overwhelming. So I wrote this post to be an easier and less overwhelming intro to the online SQL community. If you’re in the same boat, just follow these steps:
Start by following the weekly round ups (see below). At the very beginning, it’s a very good place to start.
Then if you’re still curious and your free time allows, subscribe to some of the collection feeds (see below). This gives a large variety of decent quality content.
Create a category called Elite in your RSS reader and promote or tag your favorite writers to that category.
Without further ado
Weekly SQL Article Roundups
These are weekly recaps of what’s new in SQL Server are probably the highest concentration of quality links for the week. I would recommend any one of them for anyone who only has 15 to 30 minutes to spare a week but wants to keep an eye on the industry.
Database Weekly (website | newsletter) A weekly newsletter put on by the folks at SQL Server Central (Or Red Gate or Simple Talk; they’re all friends). It’s probably the most popular weekly round up for SQL Server and well deserved. It’s got at least a couple dozen links a week. It seems like a lot, but they’re broken out into categories so it’s manageable and very comprehensive.
Something For The Weekend (website | email | rss) By John Sansom (good guy). He usually has a dozen or so handpicked articles that he posts on Fridays. If you’re in the UK, he’ll also tell you about local user group events.
Things Brent, Jeremiah, Kendra and Tim Liked This Week (website | email) Another weekly newsletter that sprouted up about a month ago. It’s not as much of a round up as the other two in this list; It’s four people selecting three or four of their favorite links weekly. It’s only been a little over a month, but these links are cool (concentrated cool) and don’t tend to overlap with the other round-ups above.
Blog Collections
If you thought that Ulysses was a nice light read; And you remember Moby Dick as a quick fable; Maybe you’ve accidentally called the phone book a pamphlet and your favorite drink is fire-hose water. Then these are for you.
These are aggregate feeds of syndicated bloggers. Why subscribe to hundreds of SQL Bloggers separately when you can subscribe to most of them in one feed? With these feeds, you’ve got tons of articles to read and will likely not have enough time to read all of them. But if you eat\breathe\sleep SQL Server, these are for you.
SQLServerPedia (website | rss) Hosted by Quest software, they’ve got about 100 bloggers and I’m proud to be one of them. It’s a syndicated list which means that each article actually lives on its own bloggers’ site. But the articles are collected by SQLServerPedia’s website and rss feed. It’s a very diverse group of bloggers and together they average about 10 to 20 articles a day.
SQLBlog (website | rss) Run by Adam Machanic and Peter DeBetta. These blogs are popular and they’ve been around a while. They’ve got about 30-ish active bloggers under their wing and the quality is top knotch. There’s a number of things that make this site stand out.
Quality, You can trust the information in these articles.
Focus, Most of the articles are technical. Occasionally there are a few posts entitled I’ll be speaking at some user group you don’t care about. But those are easy to skip.
Active, The comment section is lively. Because the articles are hosted at SQL Blog, so are the comments.
SQLServerCentral (rss) This has a couple posts a day and includes articles from Simple Talk. The volume makes keeping up with this feed manageable. The quality of each article is first class. I believe these articles are really polished because they’re reviewed by tech editors. My only gripes are that …
The feed only includes a one paragraph teaser so that you have to click through to read the articles.
Often the teaser has no indication of who the author is. So when the teaser article is something generic like Make the most of your Database it’s tempting to simply mark-as-read.
There are lots of others and I know I’m missing a few (SQLTeam, SQLskills, SSWUG etc…) you can check them out if you’re a fire-hose water connoisseur. (Holy cow, I just spelled connoisseur correctly without spell check!!)
Michael, What Else Have You Got?
If none of the above information is new to you, good job, you’re well ahead of the curve. This post still has something new for you though, a “meta” joke (a joke about “meta”, not a joke about jokes)
The humour here is all Karen Lopez (@DataChick), I just supplied the pixels.







 on the other hand")

