


SERIES: Concurrent Transaction Phenomena
In Books Online (BOL), Microsoft describes different kinds of transaction isolation levels in terms of phenomena that can occur during concurrent transactions. Specifically, they mention three kinds of phenomena: Dirty Reads, Non-Repeatable Reads, and Phantom Reads. You may have heard of these before, but correct me if I’m wrong, I just can’t find a good definition anywhere on BOL.
And that’s too bad, because these phenomena don’t just help describe the different transaction isolation levels. The phenomena actually define these levels.
These terms actually come from the ISO/ANSI standard for SQL-92. The terms themselves however do little to illuminate exactly the meaning of each. (What’s a phantom read?) When used by the ANSI/ISO standard, they mean something very specific and they’re key to understanding the different isolation levels.
In the next few days, I’d like to illustrate each phenomenon:
- Part 1: The Dirty Read (reading tentative data)
- Part 2: The Non-Repeatable Read (reading changed data)
- Part 3: The Phantom Read (reading new data)
- Part 4: Serializable vs. Snapshot
Part 4: Serializable vs. Snapshot
So I’ve finished talking about the types of transaction phenomena defined in the ISO/ANSI standard. There are two isolation levels that SQL Server supports which never experience any of these (no dirty, non-repeatable or phantom reads). They are SERIALIZABLE and SNAPSHOT. They are both made available in order to avoid dirty, non-repeatable or phantom reads, but they do so using different methods. Understanding both is the key to being able to decide whether these are right for your application.
SERIALIZABLE
Serializable is the most isolated transaction level. Basically when a transaction reads or writes data from the database, that’s what it’s going to be until the end of the transaction:
From ISO/ANSI: [Execution of concurrent SERIALIZABLE transctions are guaranteed to be serializable which is] defined to be an execution of the operations of concurrently executing SQL-transactions that produces the same effect as some serial execution of those same SQL-transactions. A serial execution is one in which each SQL-transaction executes to completion before the next SQL-transaction begins.
So that’s it! SERIALIZABLE transactions see database data as if there were no other transactions running at the same time. So no dirty, phantom or non-repeatable reads (but maybe some blocking).
It’s interesting that the standard defines SERIALIZABLE as the default level. Microsoft doesn’t subscribe to that notion and makes READ COMMITTED the default level.
The SERIALIZABLE level prevents phantom reads by using range locks. Which I explain at the end of this article.
SNAPSHOT
SNAPSHOT transactions avoid phantom reads, dirty reads and non-repeatable reads, but they do it in quite a different way than SERIALIZABLE transactions do.
While SERIALIZABLE uses locks, instead SNAPSHOT uses a copy of committed data. Since no locks are taken, when subsequent changes are made by concurrent transactions, those changes are allowed and not blocked.
So say you’re using SNAPSHOT transactions and you finally decide to make a change to some data. As far as you know, that data hasn’t changed from the first time you looked at it. But if that data has been changed elsewhere then you’ll get this error message:
Msg 3960, Level 16, State 4, Line 1
Snapshot isolation transaction aborted due to update conflict. You
cannot use snapshot isolation to access table 'dbo.test' directly or
indirectly in database 'snapshottest' to update, delete, or insert
the row that has been modified or deleted by another transaction.
Retry the transaction or change the isolation level for the
update/delete statement.
What this update conflict error message is trying to convey is exactly the same concept as Wikipedia’s Edit Conflict error message. Except that Wikipedia explains it better. I suggest looking there.
ANSI-SQL’s SNAPSHOT Definition
There isn’t one. The SNAPSHOT isolation level I’m talking about is a Microsoft thing only. They’re useful, but definitely not part of the SQL standard.
It’s not too hard to see why. The SNAPSHOT isolation level permits the database server to serve data that is out of date. And that’s a big deal! It’s not just uncommitted. It’s old and incorrect (consistent, but incorrect).
Some people place a greater value on consistency rather than timely and accurate. I think it’s nice to have the choice.
Bonus Appendix: Range Locks.
(I was tempted to break out this appendix into its own blog post but ulitmately decided not to.)
So SERIALIZABLE transactions take range locks in order to prevent Phantom Reads. It’s interesting to see what range of values is actually locked. The locked range is always bigger than the range specified in the query. I’ll show an example.
Say we have a table storing integers and insert 6 even numbers:
CREATE TABLE MyTest ( id INT PRIMARY KEY ); INSERT MyTest VALUES (2), (4), (6), (8), (10), (12); |
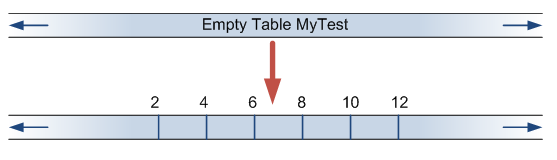
Now lets read a range:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; BEGIN TRAN SELECT id FROM MyTest WHERE id BETWEEN 3 AND 8; -- do concurrent stuff here. COMMIT |
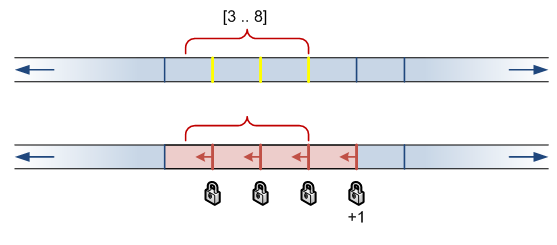
Books OnLine says: “The number of RangeS-S locks held is n+1, where n is the number of rows that satisfy the query.” We can verify this by looking at sys.dm_tran_locks. I’ve shown the locks that are taken above. Range locks apply to the range of possible values from the given key value, to the nearest key value below it.
You can see that the “locked range” of [2..10] is actually larger than the query range [3..8]. Attempts to insert rows into this range will wait.
What happens if we select a range containing all rows?
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; BEGIN TRAN SELECT id FROM MyTest WHERE id BETWEEN 1 AND 13; -- do concurrent stuff here COMMIT |
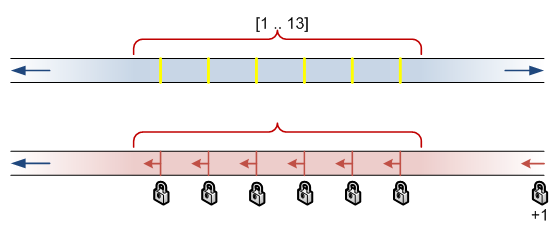
You can see that everything is selected. That lock at “infinity” has a resource_description value of (ffffffffffff).
Last interesting bit. Ghost records can participate in these ranges!
DELETE MyTest; SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; BEGIN TRAN SELECT id FROM MyTest WHERE id BETWEEN 1 AND 10; -- do concurrent stuff here COMMIT |
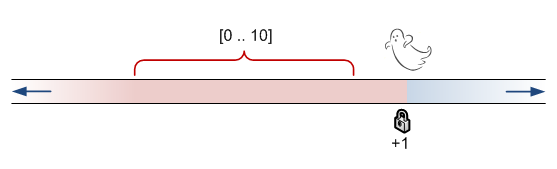
Concurrent transactions are able to insert values above 12, but will wait for values below that!




