


One of the limitations of indexed views is that their initial clustered indexes cannot be created online. Try it and you’ll get this error:
Msg 1967, Level 16, State 1, Line 34
Cannot create a new clustered index on a view online.
In Guidelines for Online Index Operations, Microsoft explicitly excludes the “Initial unique clustered index on a view” as an on-line operation. Challenge accepted.
Solution Overview
I’ll be honest. This solution is not for everyone. Especially if you don’t like to get your hands dirty.

The idea is to create a bit column in one of the base tables called IsMigrated which is initially 0. Add an extra where clause to the definition of the view IsMigrated = 1 so that the view is initially empty. Create the index and then gradually update the IsMigrated values to 1.
What follows is an example of what I mean.
The Setup
Consider these two tables I made up:

In my scenario, queries will often join these tables together and sometimes concatenate the columns BaseURL and URL. I want to create the following view and index it to facilitate URL lookups. That view looks like this.
CREATE VIEW dbo.LINK_FULLURLS WITH SCHEMABINDING AS SELECT L.LinkId, CASE WHEN L.IsExternal = 1 THEN L.URL ELSE C.BaseURL + L.URL END AS FullURL, CHECKSUM ( CASE WHEN L.IsExternal = 1 THEN L.URL ELSE C.BaseURL + L.URL END ) AS FullURLChecksum FROM dbo.LINKS L INNER JOIN dbo.CLIENTS C ON C.ClientId = L.ClientId WHERE L.DateDeleted IS NULL; |
And the base tables can get big. In my example I’ll use 50,000 clients and 200 links per client (giving 10 million rows in LINKS). So now when the initial unique clustered index is created, it can takes minutes to complete and the base tables are unavailable for the whole duration.
Offline Method
For comparison purposes, here is one offline method of creating an indexed view.
- Create the view (0 seconds)
- Scan a base table to warm up the cache (20 seconds)
- Create the initial clustered index on the view (1 minute 50 seconds offline)
- Create an additional nonclustered index on the view (2 minute 30 seconds)
Depending on the circumstances, that offline step could take longer and could be a problem. The next method attempts to get around that.
Online Method
Follow these steps
- Add a new bit column
IsMigrated(default 0) to one of the base tables. In my case I use the tableLINKSand because I’m using SQL Server 2012, this step is instantaneous (0 seconds) - Create the view (0 seconds)
- Warm up the cache by scanning the
LINKSbase table (20 seconds) - Create the initial clustered index on the view. With no writes and minimal reads this is very quick. Check it out.
/*————————
CREATE UNIQUE CLUSTERED INDEX IX_LINK_FULLURLS
ON dbo.LINK_FULLURLS(LinkId);
————————*/
Query executed successfully.
Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, …
Table ‘LINKS’. Scan count 3, logical reads 511159, physical reads 0, read-ahead reads 0, …
SQL Server Execution Times:
CPU time = 1295 ms, elapsed time = 833 ms. - Create the additional nonclustered index which is also initially empty (0 seconds)
- Change the default of
IsMigratedto 1 (0 seconds) - Update the value of
IsMigratedto 1 in batches. (8 minutes 4 seconds but online)
I don’t know if you caught it, but there is no step that removes the column IsMigrated. It stays behind messing up the data model. To remove it would require that we modify the definition of the view and that would unravel everything we did. That’s the catch.
Comparison
Here are the times that I saw:
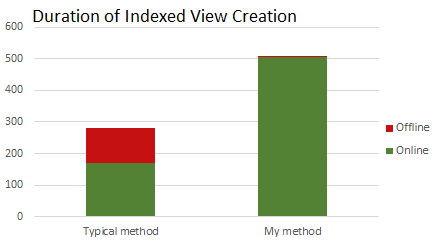
With my method, I’m not eliminating the offline step, I’m reducing its duration. It normally takes a long time to create the clustered index. I measured about half a minute of reading and two minutes of writing. My method’s offline step avoids all of the writes with the IsMigrated column and avoids most (or all) of the physical reads by warming up the cache.
Caveats and Other Notes
- The demo scripts I provided are not a recipe but an example of how to implement this strategy. If you feel like using this strategy yourself, you’re going to have to write and test your own scripts.
- This indexed view is not quite as useful as your typical indexed view. Normally SQL Server can sometimes choose to use an indexed view when executing queries that don’t even mention the view. But the extra
IsMigrated = 1clause in the view prevents SQL Server from doing so. - Other databases like Oracle and Postgres have things called Materialized Views. Those can sometimes store data that’s a bit stale, but they don’t suffer from the same online troubles that SQL Server’s Indexed View does. Sometimes the grass is greener on the other side of the fence.
- I wish I didn’t need the workaround. If you’d like to add your voice to the feedback I gave to Microsoft, then vote up this connect item Create Clustered Indexes on Views WITH (ONLINE=ON).
- I tried creating a temporary index (filtered, covering and narrow) on the base tables to help the view creation. It didn’t seem to help too much because my largest bottleneck is on writes, not reads.
- I tried creating a check constraint on
IsMigrated = 0before I created the index hoping that SQL Server could use it to reduce the reads to zero. It didn’t help.
Use Case
Like I mentioned, this method will be useful when you have no opportunity to apply offline changes to live databases and you don’t mind messing up your data model. I doubt that many will use this method. I think it’s rare to belong to an organization that can’t tolerate downtime but can tolerate this data modeling sloppiness.
If you have a large amount of development time and resources, a better way to handle this situation might be to build in some wiggle room for offline maintenance like this. A slightly more graceful alternative is to build reduced functionality into your application like the ability to disable a single feature or operate in read-only mode. This is easier said than done of course, but it accommodates a much wider variety of solutions to deployment challenges like this.

Clever!
I thought about joining a redundant table that initially contains zero rows. Then one could populate that table which would cause a huge indexed view DML to be run populating the view. This probably ends up to lock out writes, alas. Another idea would be to join a redundant table on some meaningful condition that allows for gradual population. That would not leave behind a dummy column but it would leave behind this dummy table. All DML on the view would pay a little more.
Comment by tobi — June 24, 2015 @ 12:25 pm
Thanks tobi,
I really like those creative ideas. The tradeoffs are a real struggle and I think it shows that there’s no clean solution with SQL Server as it is today.
Comment by Michael J. Swart — June 24, 2015 @ 2:50 pm
[…] How to Create Indexed Views Online – Michael J. Swart (Blog|Twitter) […]
Pingback by (SFTW) SQL Server Links 03/07/15 - John Sansom — July 3, 2015 @ 4:58 am
The idea is excellent!
I prepared a generic T-SQL script with SQLCMD parameters, after having to implement this methodology for a bunch of different tables.
Enjoy!
https://github.com/MadeiraData/MadeiraToolbox/blob/master/Utility%20Scripts/create%20an%20indexed%20view%20and%20gradually%20migrate%20data%20into%20it.sql
Comment by Eitan Blumin — March 25, 2021 @ 6:06 am
[…] The first one is from Michael J Swart (t) – How to Create Indexed Views Online. […]
Pingback by Unexpected Blocking during the Indexed View Creation – SQLServerCentral — September 8, 2022 @ 11:02 am